 订阅
订阅如何采集百度图片
来源:网络收集 点击: 时间:2024-09-03步骤1:创建采集任务
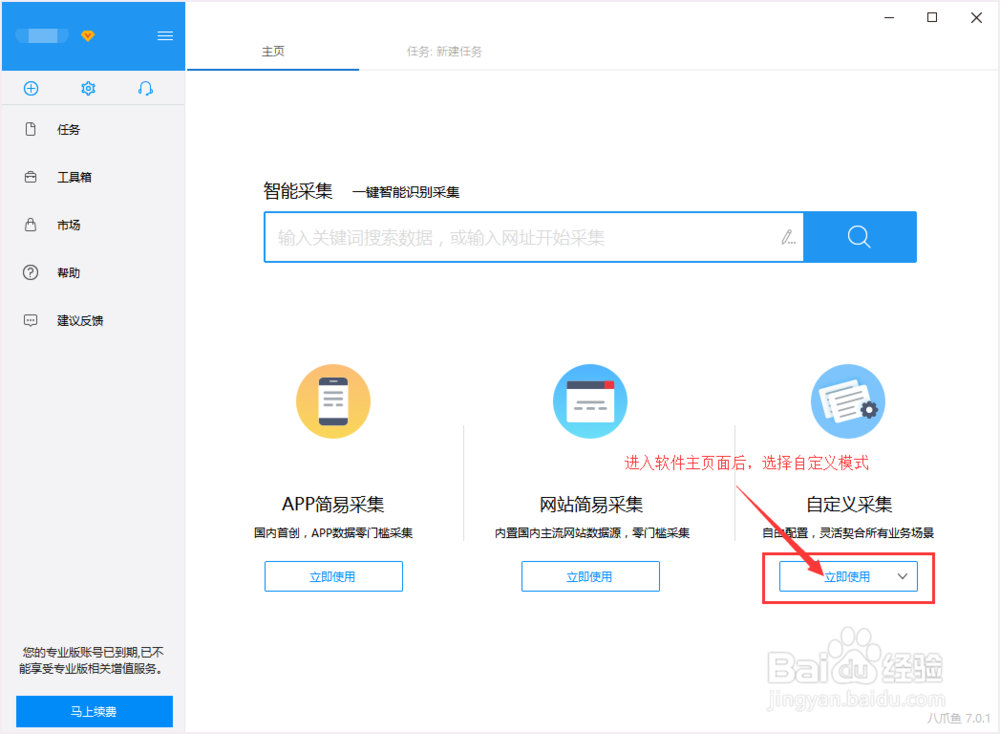
进入主界面,选择自定义模式
 2/15
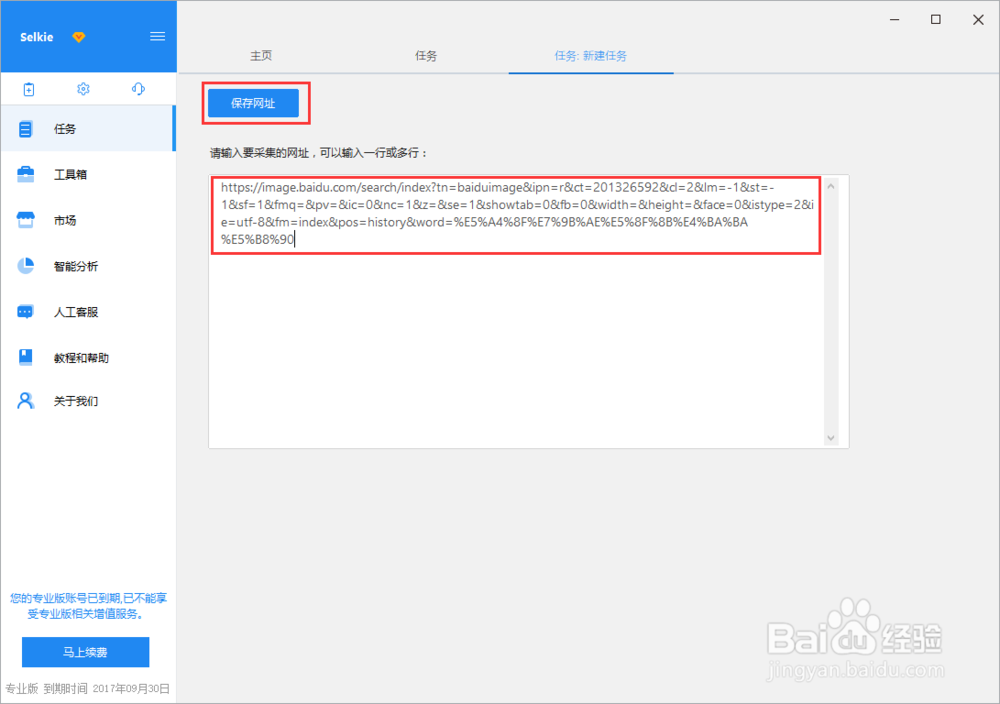
2/15将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
 3/15
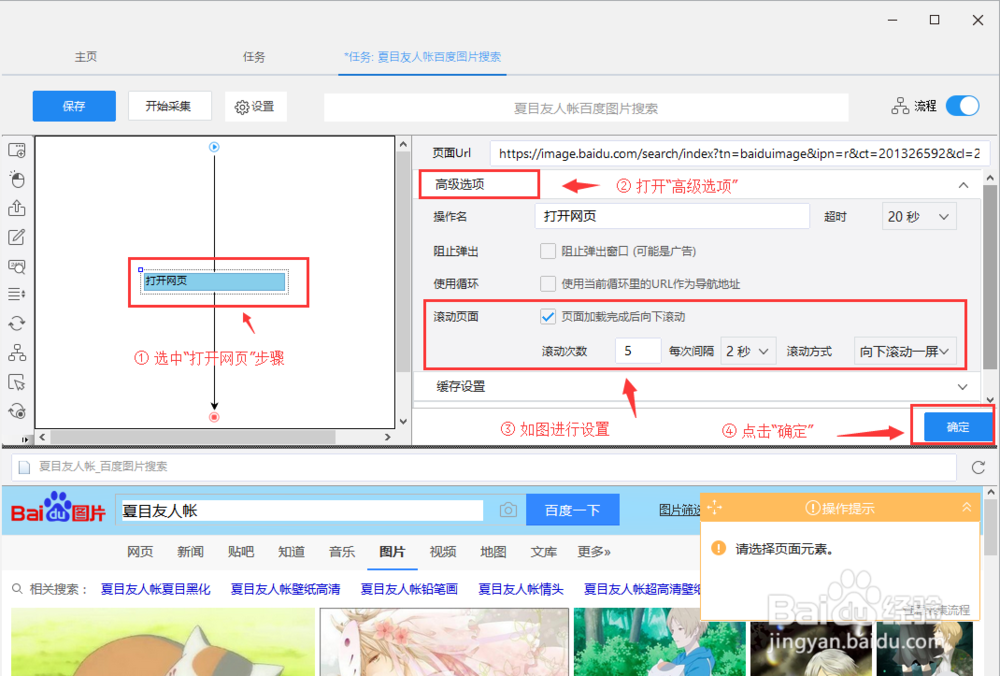
3/15系统自动打开网页。我们发现,百度图片网是瀑布流的网页,经过每一次下拉加载,都会出现新的数据。当图片足够多的时候,可无数次下拉加载。因而,此网页涉及AJAX技术,需要设置 AJAX 超时,以便确保数据采集的时候不会遗漏。
选中“打开网页”步骤,打开“高级选项”,勾选“页面加载完成向下滚动”,设置滚动次数为“5次”(根据自身需求进行设置),时间为“2秒”,滚动方式为“向下滚动一屏”;最后点击“确定”
 4/15
4/15注意:示例网站,没有翻页按钮,滚动次数、滚动方式会影响数据采集数量,可按需设置
步骤2:采集图片URL
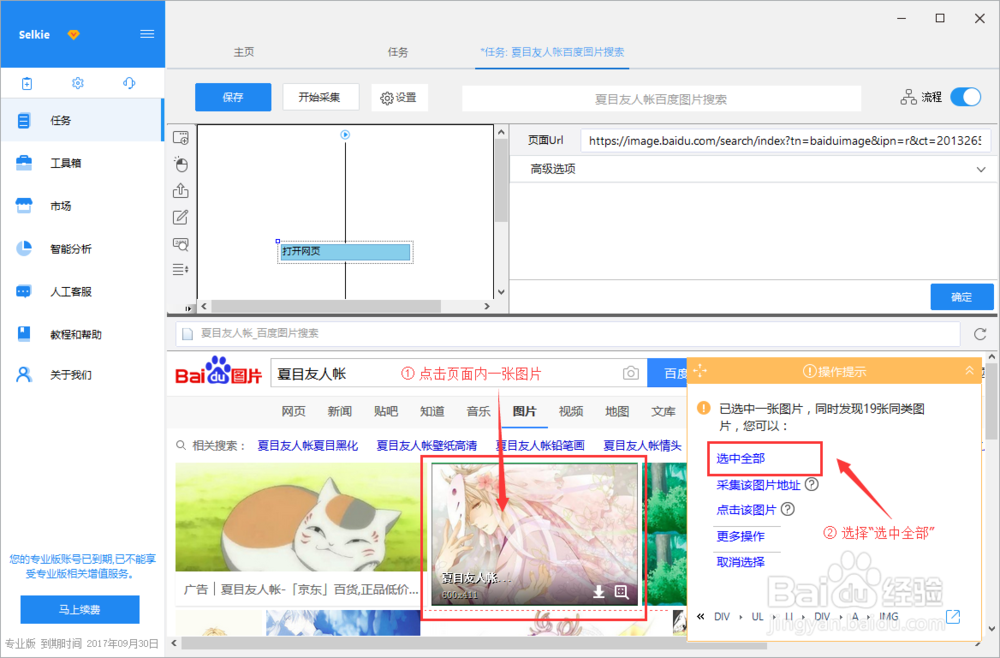
选中页面内第一个图片,系统会自动识别同类图片。在操作提示框中,选择“选中全部”
 5/15
5/15选择“采集以下图片地址”
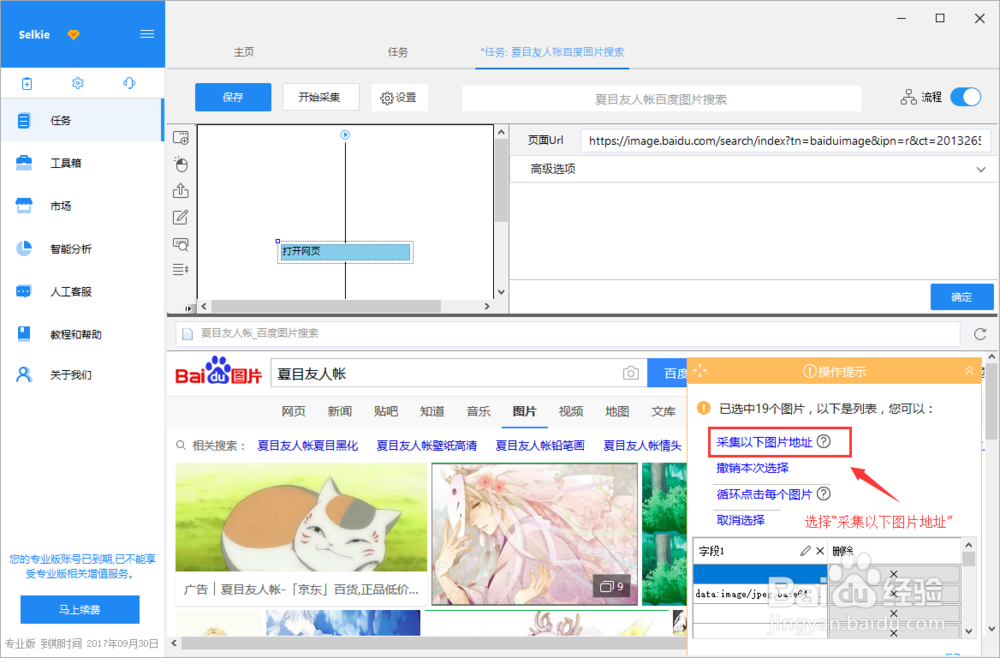 6/15
6/15步骤3:修改Xpath
选中“循环”步骤,打开“高级选项”。可以看到采集系统自动采用的是“不固定元素列表”循环,Xpath为://DIV/DIV/UL/LI
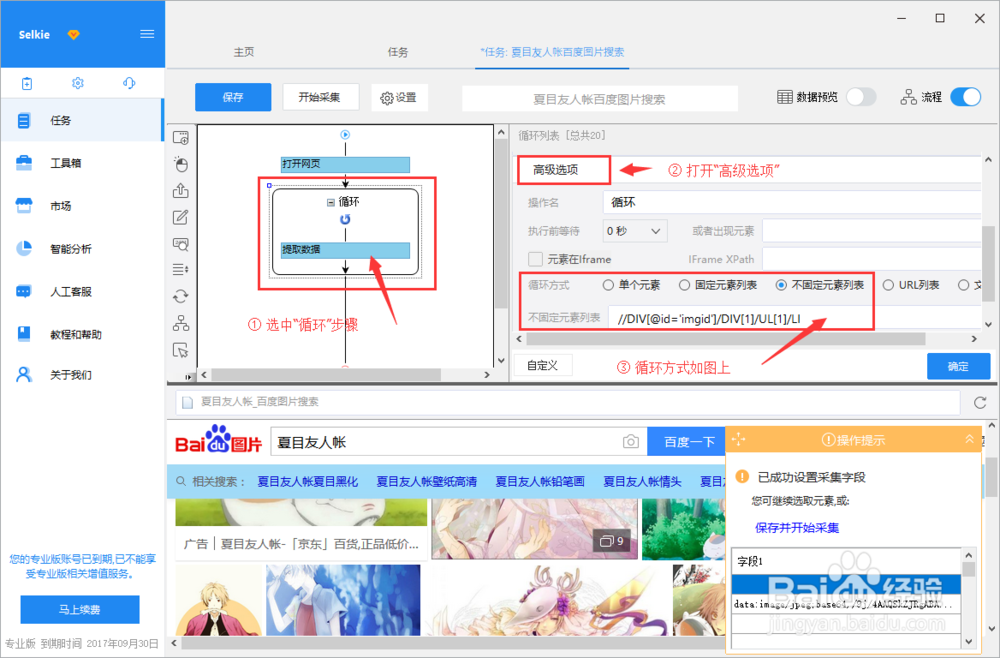 7/15
7/15将此条Xpath://DIV/DIV/UL/LI,复制到火狐浏览器中进行观察——仅可定位到网页中22张图片
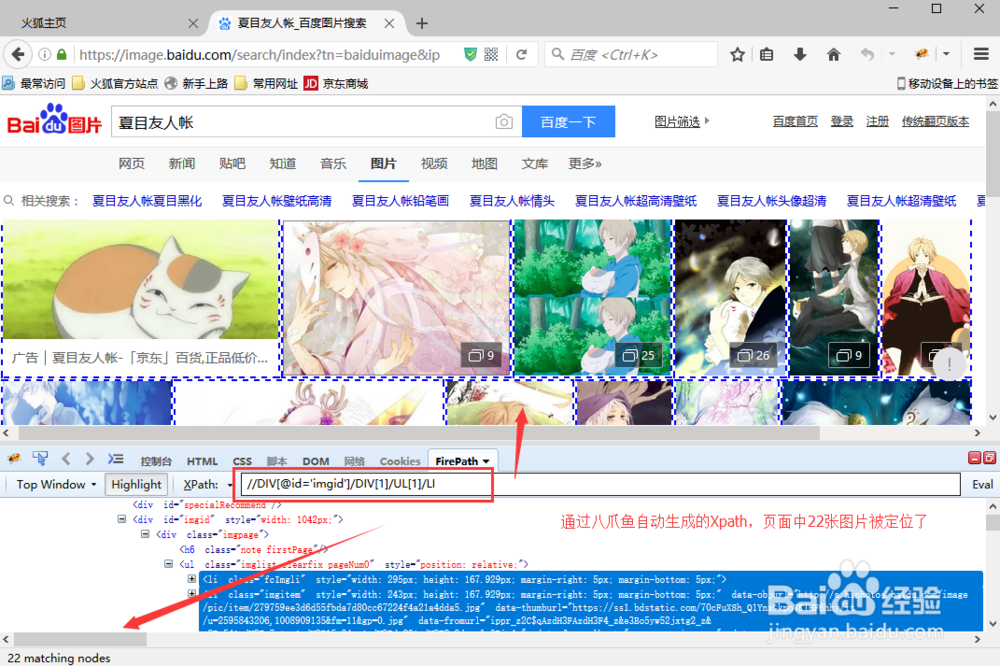 8/15
8/15我们需要一条能够定位到网页中全部所需图片的Xpath。观察网页源码并将Xpath修改为://DIV/DIV/UL/LI,网页中全部所需的图片均被定位了
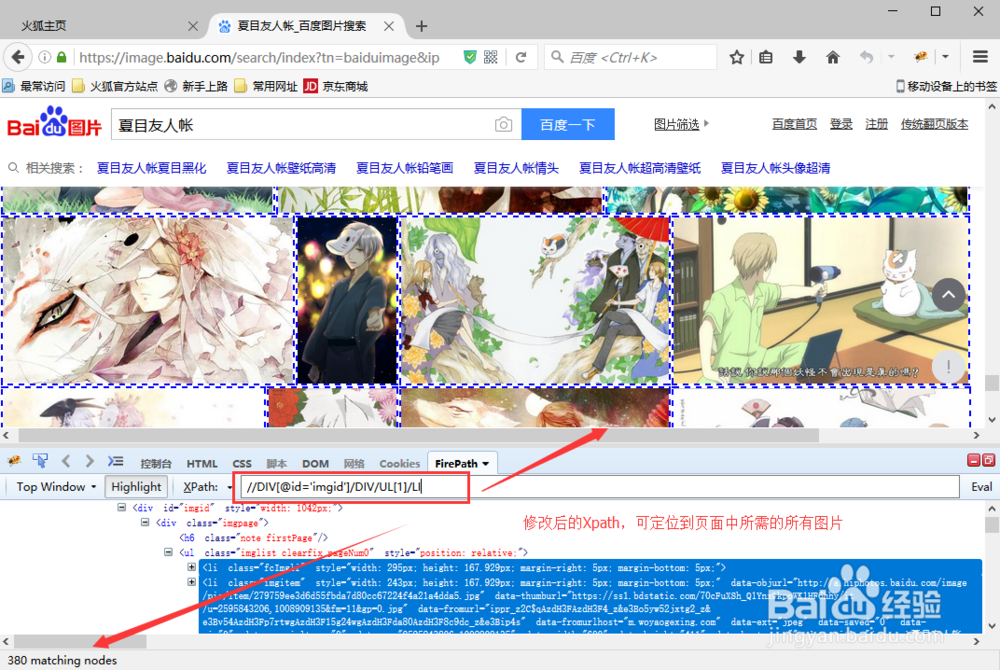 9/15
9/15将修改后的Xpath://DIV/DIV/UL/LI,复制粘贴到采集器中相应位置,完成后点击“确定”
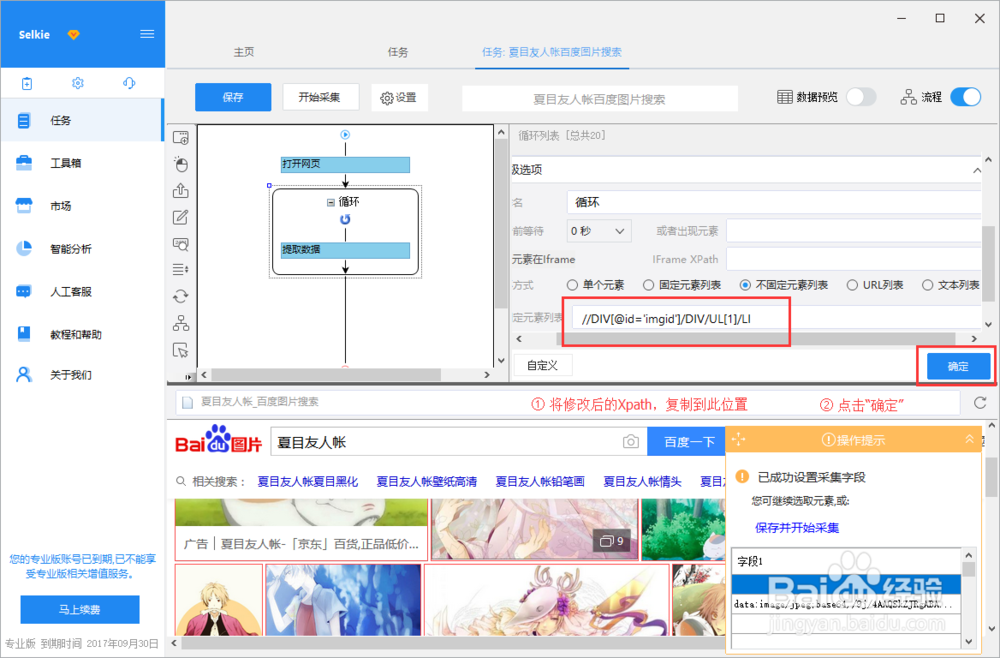 10/15
10/15点击“保存”,再点击“开始采集”,这里选择“启动本地采集”
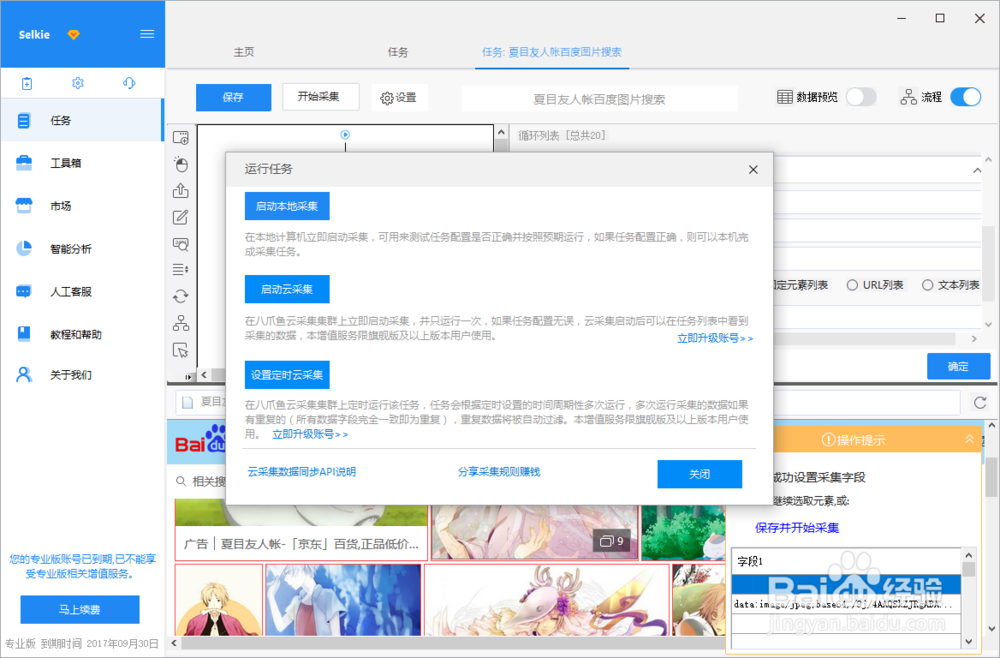 11/15
11/15说明:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
步骤4:数据采集及导出
采集完成后,会跳出提示,选择导出数据
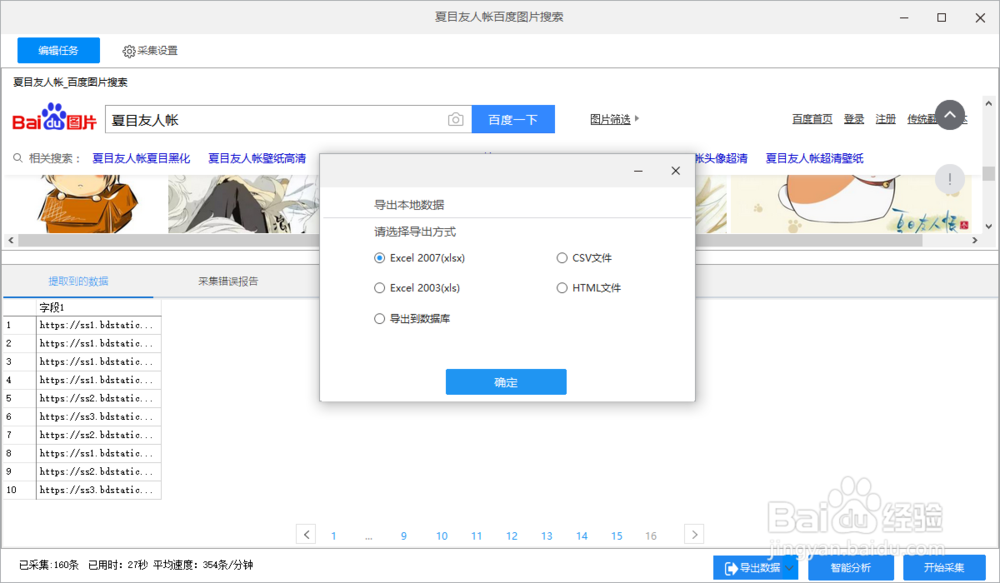 12/15
12/15选择合适的导出方式,将采集好的数据导出
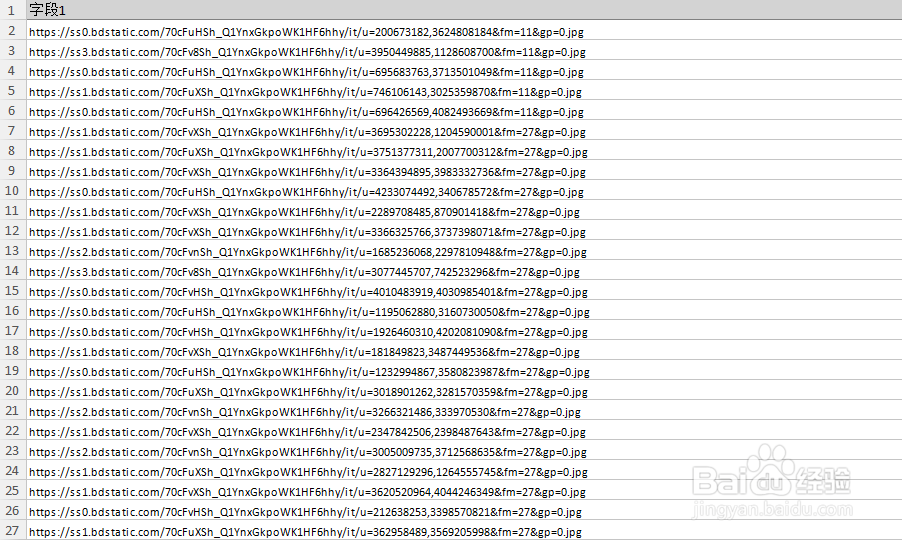 13/15
13/15步骤5:将图片URL批量转换为图片
经过如上操作,我们已经得到了要采集的图片的URL。接下来,再通过采集器专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。
图片批量下载工具:https://pan.baidu.com/s/1c2n60NI
下载采集器图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件
 14/15
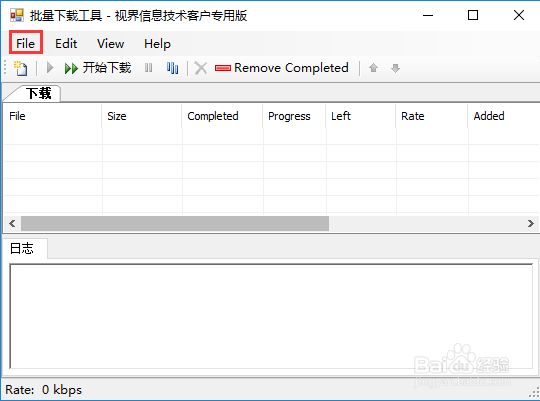
14/15打开File菜单,选择从EXCEL导入(目前只支持EXCEL格式文件)
 15/15
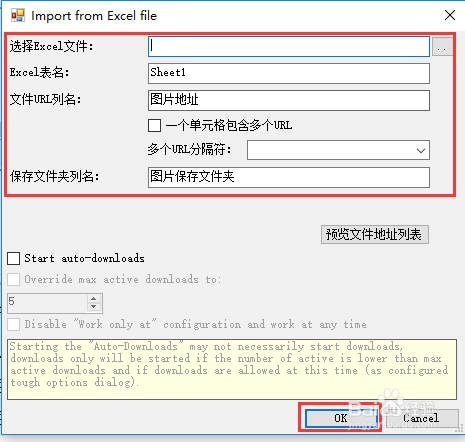
15/15进行相关设置,设置完成后,点击OK即可导入文件
选择EXCEL文件:导入你需要下载图片地址的EXCEL文件
EXCEL表名:对应数据表的名称
文件URL列名:表内对应URL的列名称
保存文件夹名:EXCEL中需要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片存放至不同文件夹
如果要把文件保存到文件夹,则路径需要以“\”结尾,例如:“D:\同步\”,如果要下载后按照指定的文件名保存,则需要包含具体的文件名,例如“D:\同步\1.jpg”
如果下载的文件路径和文件名完全一样,则原先存在的文件会被删除
 百度图片采集百度采集网页采集
百度图片采集百度采集网页采集 版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_1194411.html