 订阅
订阅爬取数据链接不在源码里怎么处理
来源:网络收集 点击: 时间:2024-09-08【导读】:
网站为了保护自己的数据或者网站架构原因,会把一部分数据藏起来,并不直接展示在源码中,但这部分数据真实存在。隐藏的链接通常存在于js或者json等文件中。我们只要分析出这部分文件所在的位置,通过正则等方式提取就可以。工具/原料morefiddler浏览器方法/步骤1/4分步阅读
 2/4
2/4
 3/4
3/4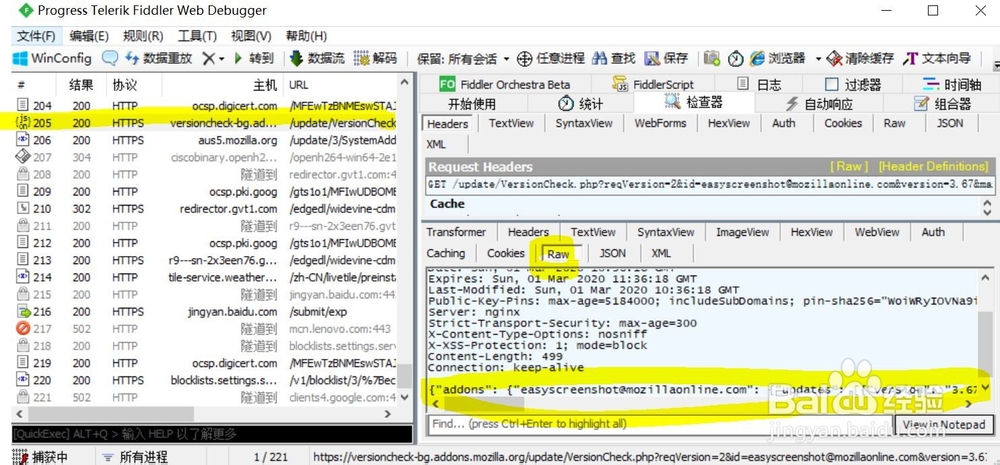 4/4
4/4
下载fiddler安装包,安装fiddler。我这是直接从安装包中打开fiddler.exe文件,及fiddler首次打开后的样子。
2/4可以绑定fidder与一个特定的浏览器,防止正常请求响应太慢。这里以火狐浏览器为例,通过:设置》选项》代理设置进入火狐代理设置页面,将火狐与fiddler绑定,使得每次火狐请求的服务器返回的响应经过fiddler。具体设置信息见第二张图。
3/4在火狐浏览器中打开目标网站,打开fiddler,fiddler左侧双击打开fiddler中的json文件、js文件等文件,右侧查看响应返回的内容。图中,如,左侧打开某个网站返回的205号json文件,右侧row中查看这个文件中的包含了一系列的json数据,对比分析返回的json数据是否包含目标数据,如不包含,则继续打开其他链接可能存在的文件,找到为止。
4/4在找到数据存在的文件后,在fiddler左侧文件位置右键,复制文件的url,获取url中的目标数据信息即可。
版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_1200215.html
上一篇:简笔画---怎么画望远镜
下一篇:PPT【节】的定义和设置方法