 订阅
订阅网站爬虫时,如何快捷获取浏览器的User-Agent?
来源:网络收集 点击: 时间:2024-03-03【导读】:
user–agent的意思是用户代理,简称UA。我们在爬取网站内容的时候,如果没有对UA进行设置,服务器将拒绝我们的请求,所以我们要设置UA的内容。但是有些人在写爬虫代码时不知道如何设置UA,这里介绍下如何获取浏览器UA的详细步骤。工具/原料more电脑/网络浏览器方法/步骤1/5分步阅读 2/5
2/5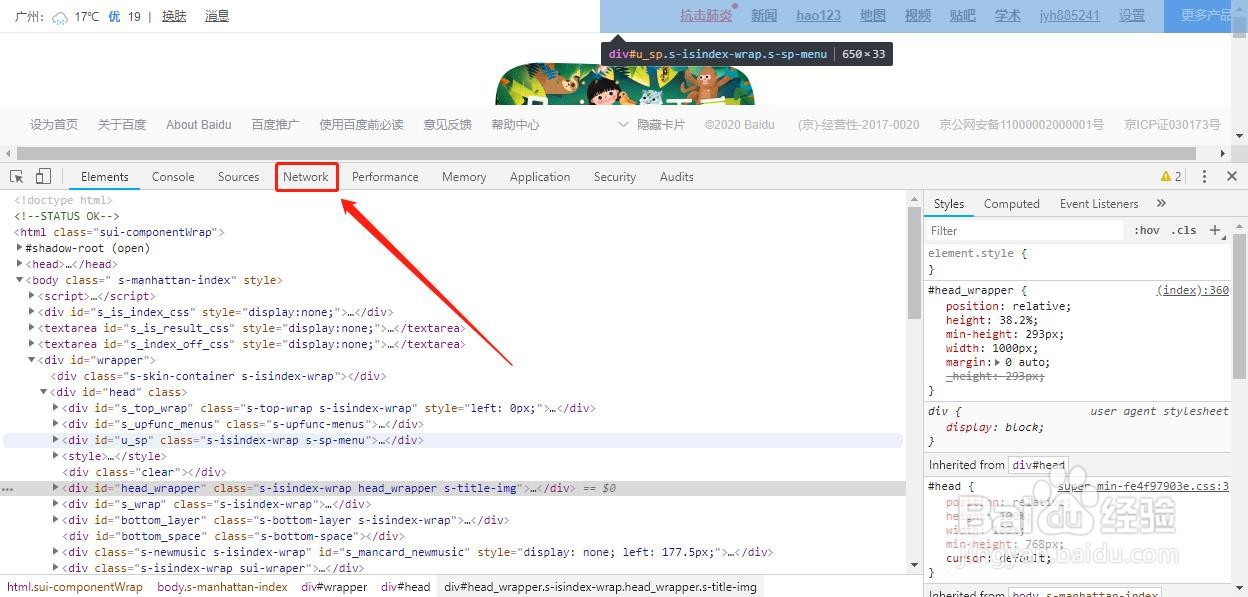 3/5
3/5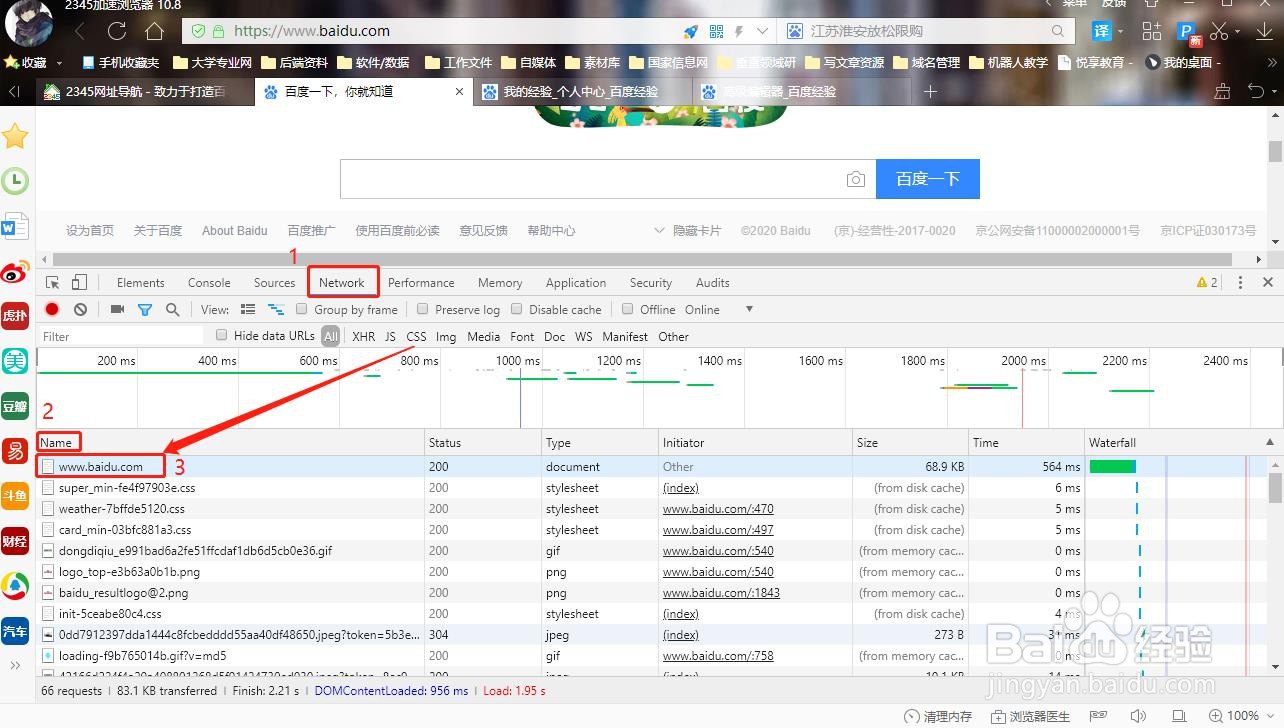 4/5
4/5 5/5
5/5 注意事项
注意事项
第一步,在任意浏览器页面右击,找到审查元素,或者是查看网页源代码。一般情况下,不同的浏览器有不同的进入方式,还有一个更快捷的方式:按F12直接进入HTML后台。
2/5第二步,进入到开发者工具中,进入后首先看到的是HTML代码,我们点击图中的Network,进入到网络请求信息中心。
3/5第三步,找到Name中的网址信息。
注意,进入的网页网址不同,查找的内容也不同,请查找自己的网址并点击。
4/5第四步,点击网址之后,会出现Headers和Cookie等信息,我们找到Headers中的请求头Request Headers。因为user-agent是在HTTP请求当中发送到服务器的。
5/5第五步,找到User-Agent,这里的内容包含的就是我们使用的浏览器类型、操作系统及版本、CPU 类型、浏览器渲染引擎、浏览器语言、浏览器插件等信息,然后将此信息复制粘贴到我们爬虫的代码中即可。
注意事项注意每个浏览器进入到开发者工具的方式都不一样,不过按键F12应该是通用的。
浏览器UA标识网络爬虫获取UA版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_224500.html
上一篇:简单的短袖怎么剪
下一篇:vscode怎么在终端显示结果