 订阅
订阅Python中如何使用k-近邻算法对手写数字进行识别
来源:网络收集 点击: 时间:2024-03-11(1)收集数据:提供文本文件
将需要识别的数字使用图形处理软件,处理成32像素×32像素的黑白图像,并将图像转换为文本格式。
1)训练数据集trainingDigits:用于训练分类器,其中包含了大约2000个例子,每个例子的内容下图所示,每个数字大约有200个样本;
2)测试数据集testDigits:用于测试分类器的效果,其中中包含了大约900个测试数据。


 2/6
2/6(2)准备数据:编写函数classify0(),将图像格式转换为分类器使用的list格式。
将图像格式化处理为一个向量:即把一个32×32的二进制图像矩阵转换为1×1024的向量,这样就可以使用分类器来处理数字图像信息了。
此功能是用函数img2vector来实现的:
1)创建1×1024的NumPy数组
2)打开给定的文件,循环读出文件的前32行,并将每行的头32个字符值存储在NumPy数组中,最后返回数组。
 3/6
3/6(3)分析数据:在Python命令提示符中检查数据,确保它符合要求。
将上述代码输入到kNN.py文件中,在Python命令行中输入下列命令,对img2vector函数进行测试,然后与文本编辑器打开的文件进行比较:
testVector =kNN.img2vector(D://mymodule/testDigits/0_13.txt)
testVector
注:每个人testDigits文件位置不一样,把D://mymodule/testDigits/0_13.txt修改成自己的文件路径
 4/6
4/6(4)训练算法:对k近邻算法来说,一般此步骤可以省略。
(5)测试算法:编写函数使用提供的部分数据集作为测试样本(已经完成分类的数据),如果预测分类与实际类别不同,则标记为一个错误。
将第(2)步处理好的数据输入到分类器,检测分类器的执行效果。
此处,用函数handwritingClassTest()来完成测试分类器,将其写kNN.py文件中。
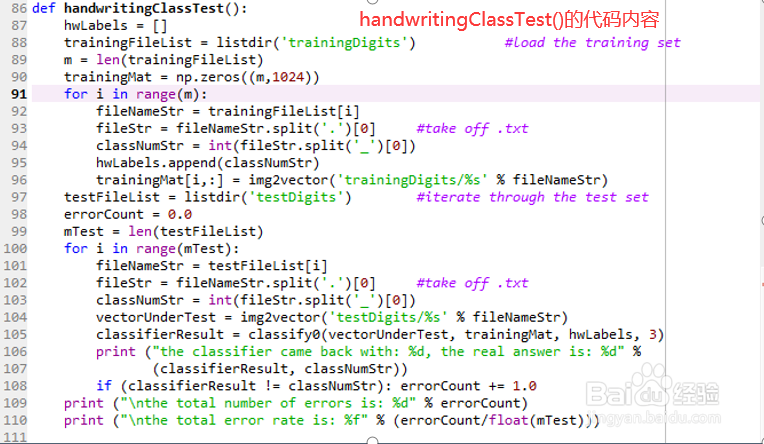 5/6
5/6(6) 使用算法:
在Python命令提示符中输入kNN.handwritingClassTest(),测试该函数的输出结果。
注:此过程会比较长,请耐心等待。
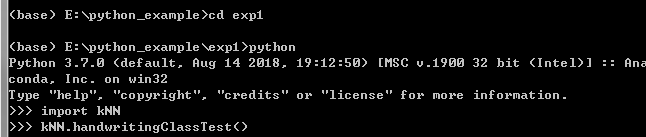 6/6
6/6(7)判断结果
k-近邻算法识别手写数字数据集,错误率为1.0571%。改变变量k的值、修改函数handwriting-ClassTest随机选取训练样本、改变训练样本的数目,都会对k-近邻算法的错误率产生影响 。
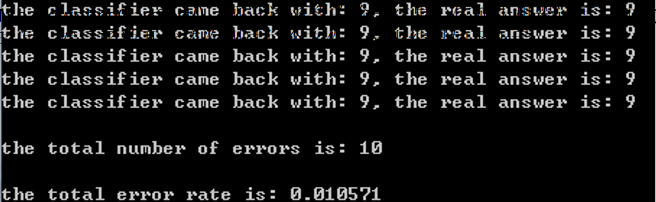 注意事项
注意事项依赖于机器速度,加载数据集可能需要花费很长时间
符合标准的路径格式:(1)双引号+双斜杠 (2)单引号+反斜杠
#trainingFileList = listdir(E:\\python_example\\exp1\\digits\\trainingDigits\\)或者 trainingFileList = listdir(E:/python_example/exp1/digits/trainingDigits)
如果在spyder中修改后,在anaconda prompt中,一定要先“ctrl+Z”,然后重新import kNN才起作用。
版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_319989.html