 订阅
订阅如何使用Python实现根据网址采集网页?
来源:网络收集 点击: 时间:2024-03-14【导读】:
Python是现在很流行的一种编程语言,以其功能的强大深受程序员的喜爱。下面小编就为大家介绍如何使用Python实现根据网址采集网页。快来看看吧。方法/步骤1/5分步阅读引入模块“urllib2”。 2/5设置要采集的地址:url=‘http://www.baidu.com/’。
2/5设置要采集的地址:url=‘http://www.baidu.com/’。 3/5使用“urlopen”方法返回网页文件:a=urllib.request.urlopen(url)。
3/5使用“urlopen”方法返回网页文件:a=urllib.request.urlopen(url)。 4/5只能使用“read”方法获取网页文件的内容:f=a.read()。
4/5只能使用“read”方法获取网页文件的内容:f=a.read()。 5/5看一下“f”的长度就知道是否真的返回了网页:len(f)。
5/5看一下“f”的长度就知道是否真的返回了网页:len(f)。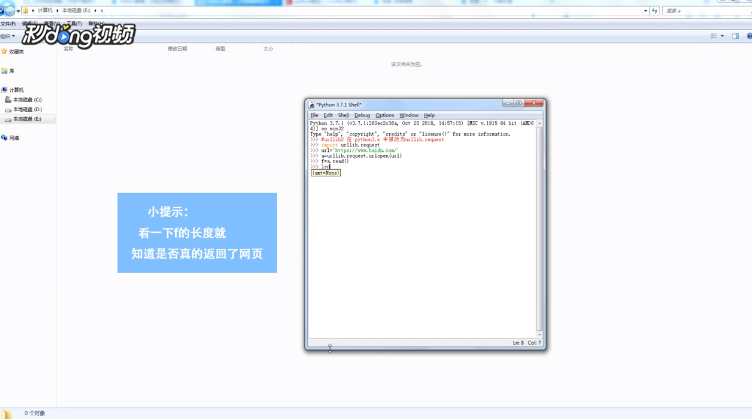
2/5设置要采集的地址:url=‘http://www.baidu.com/’。3/5使用“urlopen”方法返回网页文件:a=urllib.request.urlopen(url)。4/5只能使用“read”方法获取网页文件的内容:f=a.read()。5/5看一下“f”的长度就知道是否真的返回了网页:len(f)。 版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_350946.html
上一篇:美团个性化内容推荐怎么关闭
下一篇:sh文件怎么运行