 订阅
订阅python用百度文字识别功能识别验证码登陆网站
来源:网络收集 点击: 时间:2024-01-25导入本例所需要的模块,
from aip import AipOcr
import time
from selenium import webdriver
import json
from configparser import ConfigParser
其中第一行代码为百度文字识别用模块,第3行为本例的重点,它可以像人一样自动操作浏览器,安装方法是pip install selenium
 2/13
2/13建立一个浏览器实例driver,并用它打开需要登陆的页面。首先运行看是否能打开网站。
driver=webdriver.Chrome()
driver.get(需要登陆页面地址)
 3/13
3/13运上面的代码就打开了该网站的登陆页面。
 4/13
4/13利用selenium的find_element_by_xpath方法获得用户名输入框并向其传入用户名,方法是send.keys(用户名字符串)。
 5/13
5/13将上面的代码运和看结果。已经正确填入了账号。
 6/13
6/13同账号一样作出填入密码的方法。
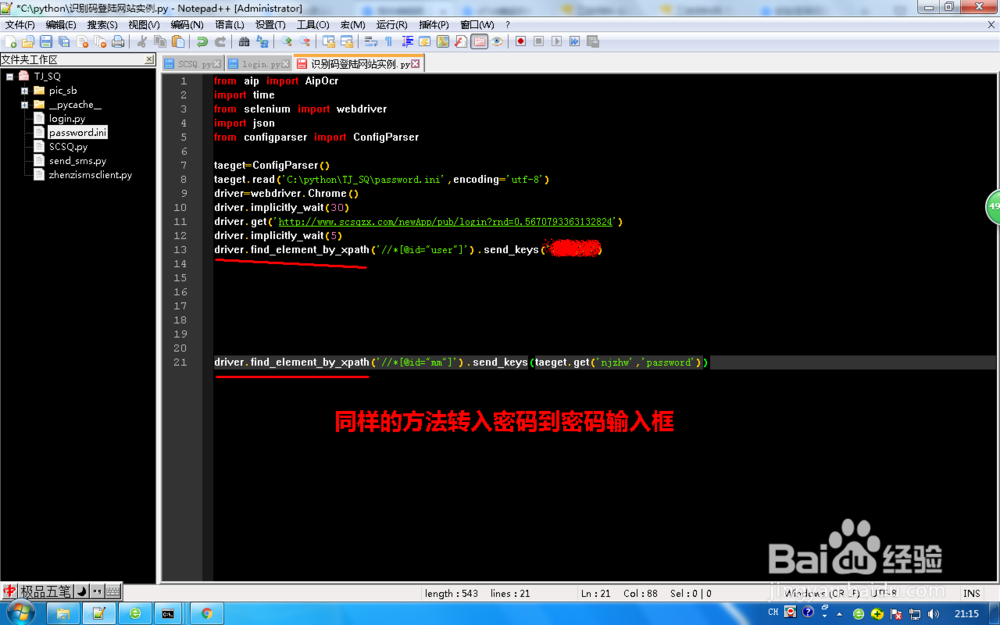 7/13
7/13获得验证码区域,本例的验证码需要验证码输入框获得焦点才会显示,所以需要在验证码输入框中发送一个单击(click())的方法。获得验证码区域,本例未精确截取验证码,截的一个大区域。
 8/13
8/13运行截屏程序,看验证码情况。将整个画面截屏保存,
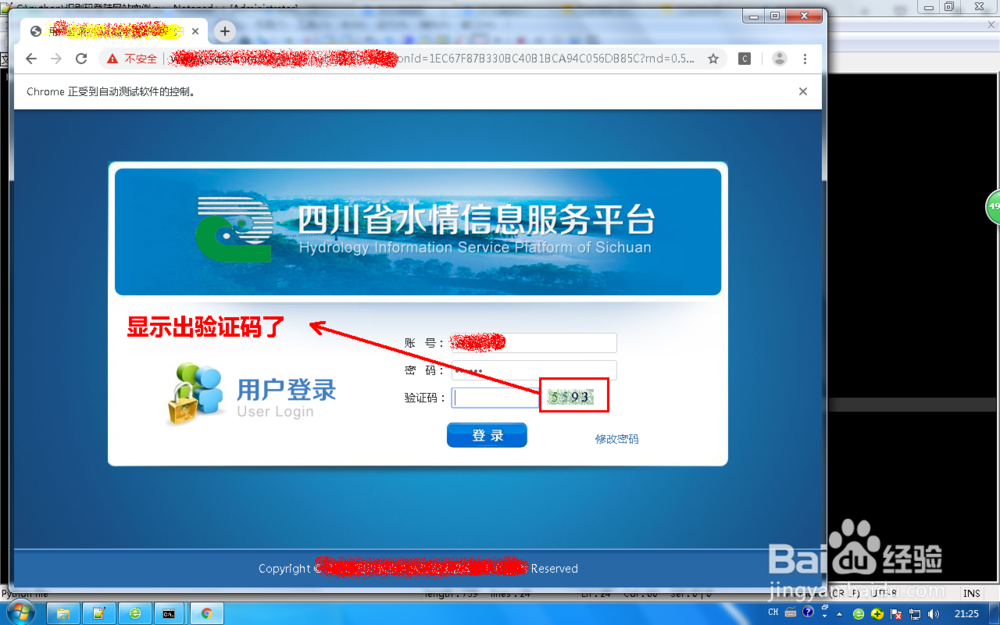 9/13
9/13有验证码的页面被截展保存成功。
 10/13
10/13对保存的图片进行文字识别,并返回结果存于text字典中。
 11/13
11/13再次运行,可以看出已分析出验码证返回在text字典中的words_result键中,处于第6个位置,值为words
可以通过code=text代码将验证码存入变量code中。
因为这个登陆页面始终是不变的,所以验证码在字典中始终是第6位上。通过这文自动识别出了验证码。
 12/13
12/13将识别后的验证码code通过selenium的send.keys()方法输入到验证码框。再向登陆按纽发送click()方法实现登陆。
 13/13
13/13成功登陆,整个过程完全无需要人工干预,全自动进行。
 PYTHON程序开发
PYTHON程序开发 版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_6422.html