 订阅
订阅微生物群落多样性测序与功能分析
来源:网络收集 点击: 时间:2024-05-0616s rDNA分析基本流程:
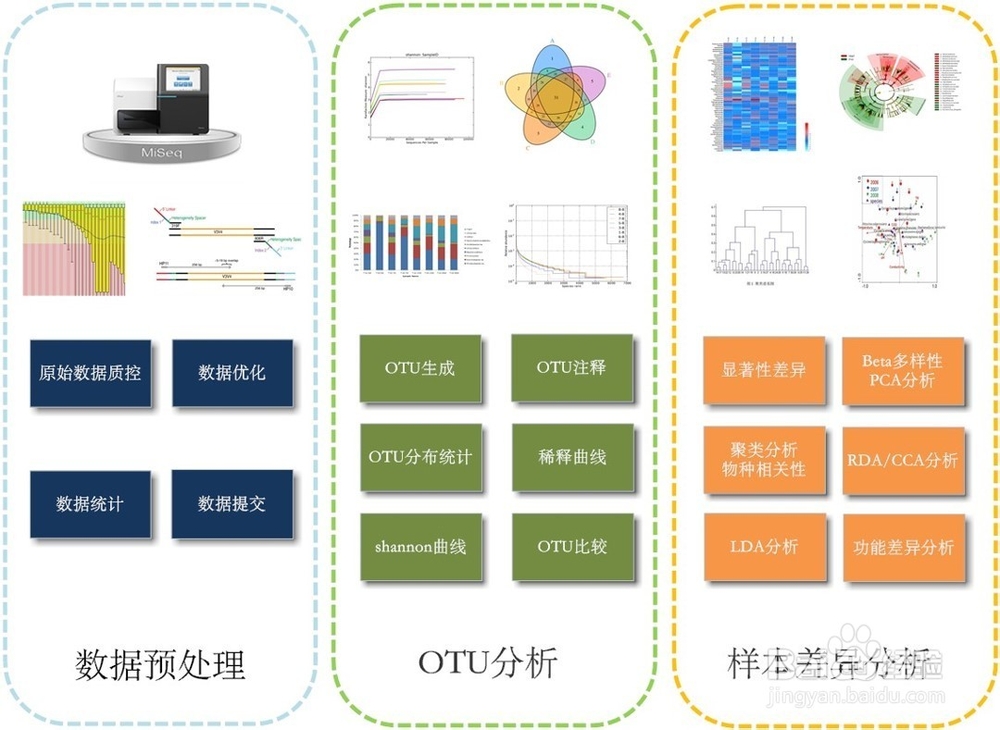 2/36
2/36原始数据处理:
原始测序数据需要去除接头序列,根据 overlap 并将双端测序序列进行拼接成单条序列,同时对序列质量进行质控和过滤。提供已知数据库 GreenGenes 作为参考,去除嵌合体序列得到最终可用的序列。
提取出的数据以 fastq 格式保存,每个样本有 fq1 和 fq2两个文件,里面为测序两端的 reads,序列按顺序一一对应。
原始fastq格式是一个文本格式用于存储生物序列(通常是核酸序列)和其测序对应的质量值。这些序列以及质量信息用ASCII字符标识。
3/36OTU分类和统计:
OTU(operational taxonomic units) 是在系统发生学研究或群体遗传学研究中,为了便于进行分析,人为给某一个分类单元(品系,种,属,分组等)设置的同一标志。通常按照 97% 的相似性阈值将序列划分为不同的 OTU,每一个 OTU 通常被视为一个微生物物种。相似性小于97%就可以认为属于不同的种,相似性小于93%-95%,可以认为属于不同的属。样品中的微生物多样性和不同微生物的丰度都是基于对OTU的分析。
使用QIIME(version 1.8.0)工具包进行统计注释。
使用QIIME(version 1.9.0, http://bio.cug.edu.cn/qiime/)的ucluster方法根据97%的序列相似度将所有序列进行同源比对并聚类成operational taxonomic units (OTUs)。然后与数据库GreenGenes(version gg_13_8, http://greengenes.lbl.gov/cgi-bin/JD_Tutorial/nph-16S.cgi)进行比对,比对方法uclust,identity 0.9 。
然后对每个OTUs进行reads数目统计。
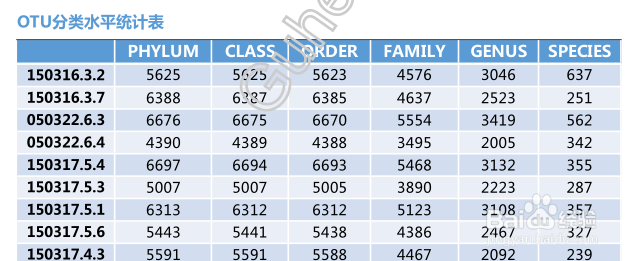
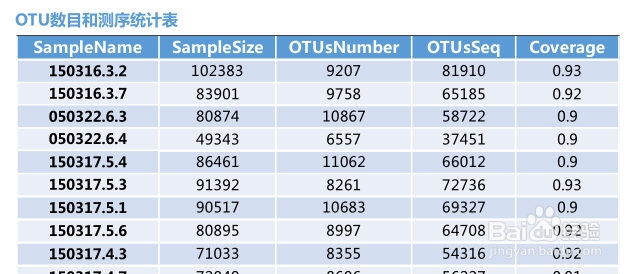
下面的2个表,其中一个表是对每个样本的测序数量和OTU数目进行统计,并且在表栺中列出了测序覆盖的完整度(显示前10个样本)。
另一个表是对每个样本在分类字水平上的数量进行统计,并且在表栺中列出了在每个分类字水平上的物种数目(显示前10个样本)。
可以看到绝大部分的OTU都分类到了属(Genus),也有很多分类到了种(Species)。但是仍然有很多无法完全分类到种一级,这是由于环境微生物本身存在非常丰富的多样性,还有大量的菌仍然没有被测序和发现。
测序数目统计表主要是对每个样本的测序数量和OTU数目进行统计,并且在表格中列出了测序覆盖的完整度(显示前10个样本,如果样本超过10个,请查看结果中otu_stat.txt文件)
其中 SampleName表示样本名称;SampleSize表示样本序列总数;OTUsNumber表示注释上的OTU数目;OTUsSeq表示注释上OTU的样本序列总数。
Coverage是指各样品文库的覆盖率,其数值越高,则样本中序列没有被测出的概率越低。该指数实际反映了本次测序结果是否代表样本的真实情况。
计算公式为:C=1-n1/N 其中n1 = 只含有一条序列的OTU的数目; N = 抽样中出现的总的序列数目。
分类水平统计表主要是对每个样本在分类学水平上的数量进行统计,并且在表格中列出了在每个分类学水平上的物种数目(只显示前10个样本,如果样本超过10个,请查看结果中taxon_all.txt文件)
其中SampleName表示样本名称;Phylum表示分类到门的OTU数量;Class表示分类到纲的OTU数量;Order表示分类到目的OTU数量;Family表示分类到科的OTU数量;Genus表示分类到属的OTU数量;Species表示分类到种的OTU数量。
 4/36
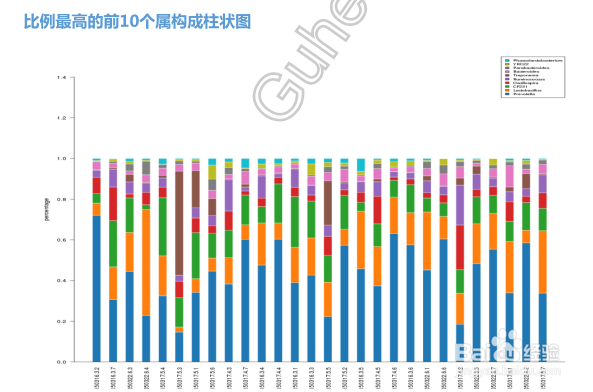
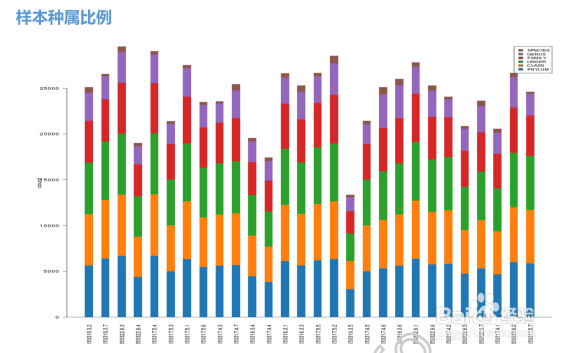
4/36我们还可以对这些种属的构成进行柱状图显示:
横坐标中每一个条形图代表一个样本,纵坐标代表该分类层级的序列数目或比例。同一种颜色代表相同的分类级别。图中的每根柱子中的颜色表示该样本在不同级别(门、纲、目等)的序列数目,序列数目只计算级别最低的分类,例如在属中计算过了,则在科中则不重复计算。
Q: 为什么要选择V3-V4区的测序长度?为什么有些文献是V6区,有什么区别?
A: 16S rRNA总长约1540 bp,包含 9个可变区。由于高通量测序的测序长度的限制,不可能将16S rRNA的9个可变区全部测序,所以在PCR扩增时往往只能选择1-3个可变区作为扩增片段。Kozich 等评估了Miseq测序仪分析的不同16S rRNA可变区的准确性发现,测定 V4 区效果最佳。根据我们的测序长度,v3-v4区是最佳选择。
 5/36
5/36我们还需要对样本之间或分组之间的OTU进行比较获得韦恩图:
注意,韦恩图目前一般最多只能显示5个样本或分组,过多的样本无法无法进行韦恩图绘制
 6/36
6/36样品构成丰度:
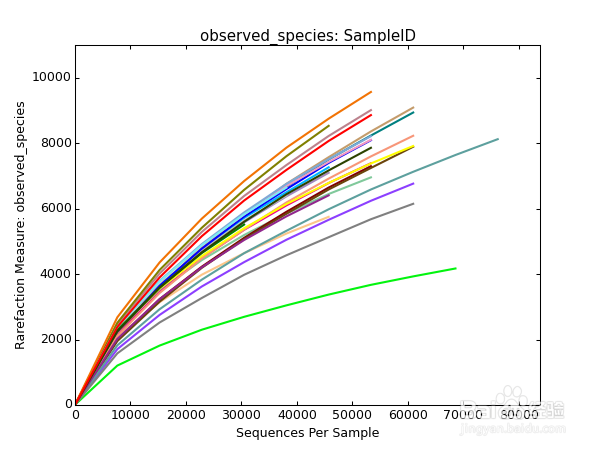
稀释曲线
微生物多样性分析中需要验证测序数据量是否足以反映样品中的物种多样性,稀释曲线(丰富度曲线)可以用来检验这一指标。
稀释曲线是用来评价测序量是否足以覆盖所有类群,并间接反映样品中物种的丰富程度。稀释曲线是利用已测得16S rDNA序列中已知的各种OTU的相对比例,来计算抽取n个(n小于测得reads序列总数)reads时出现OTU数量的期望值,然后根据一组n值(一般为一组小于总序列数的等差数列)与其相对应的OTU数量的期望值做出曲线来。当曲线趋于平缓或者达到平台期时也就可以认为测序深度已经基本覆盖到样品中所有的物种;反之,则表示样品中物种多样性较高,还存在较多未被测序检测到的物种。
下图中的稀释曲线
横坐标代表随机抽取的序列数量;纵坐标代表观测到的OTU数量。样本曲线的延伸终点的横坐标位置为该样本的测序数量,如果曲线趋于平坦表明测序已趋于饱和,增加测序数据无法再找到更多的OTU;反之表明不饱和,增加数据量可以发现更多OTU。
 7/36
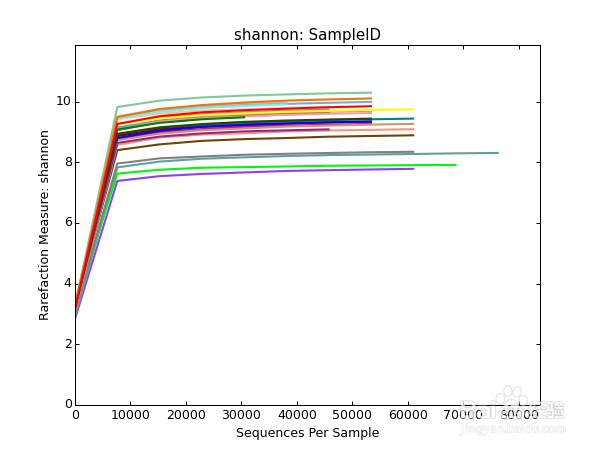
7/36Shannon-Winner曲线
Shannon-Wiener 曲线,是利用shannon指数来进行绘制的,反映样品中微生物多样性的指数,利用各样品的测序量在不同测序深度时的微生物多样性指数构建曲线,以此反映各样本在不同测序数量时的微生物多样性。 当曲线趋向平坦时,说明测序数据量足够大,可以反映样品中绝大多数的微生物物种信息。
与上图一样,横坐标代表随机抽取的序列数量;纵坐标代表的是反映物种多样性的Shannon指数。
样本曲线的延伸终点的横坐标位置为该样本的测序数量,如果曲线趋于平坦表明测序已趋于饱和,增加测序数据无法再找到更多的OTU;反之表明不饱和,增加数据量可以发现更多OTU。
其中曲线的最高点也就是该样本的Shannon指数,指数越高表明样品的物种多样性越高。
Q: Shannon指数怎么算的?
A: Shannon指数公式:
其中,Sobs=实际测量出的OTU数目;ni=含有i 条序列的OTU数目;N=所有的序列数。
 8/36
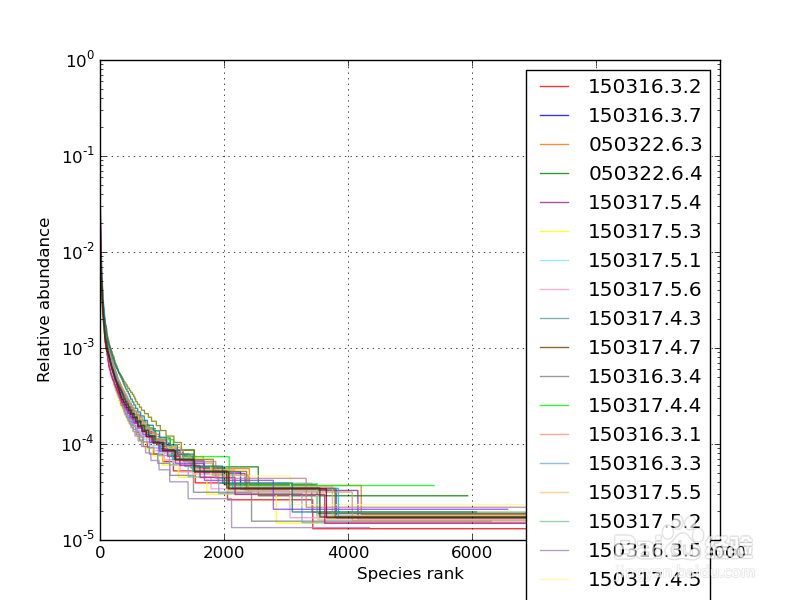
8/36Rank-Abundance曲线
用于同时解释样品多样性的两个方面,即样品所含物种的丰富程度和均匀程度。
物种的丰富程度由曲线在横轴上的长度来反映,曲线越宽,表示物种的组成越丰富;
物种组成的均匀程度由曲线的形状来反映,曲线越平坦,表示物种组成的均匀程度越高。
一般超过20个样本图就会变得非常复杂而且不美观,所以一般20个样本以下会做该图,图片保存为结果目录中rank.pdf。
横坐标代表物种排序的数量;纵坐标代表观测到的相对丰度。
样本曲线的延伸终点的横坐标位置为该样本的物种数量,如果曲线越平滑下降表明样本的物种多样性越高,而曲线快速陡然下降表明样本中的优势菌群所占比例很高,多样性较低。
 9/36
9/36Alpha多样性(样本内多样性)
Alpha多样性是指一个特定区域或者生态系统内的多样性,常用的度量指标有Chao1 丰富度估计量(Chao1 richness estimator) 、香农 - 威纳多样性指数(Shannon-wiener diversity index)、辛普森多样性指数(Simpson diversity index)等。
计算菌群丰度:Chao、ace;
计算菌群多样性:Shannon、Simpson。
Simpson指数值越大,说明群落多样性越高;Shannon指数越大,说明群落多样性越高。表中显示前10个样本,如果样本大于10个,详见结果目录中的alpha_div.txt。
Q: 能不能解释下每个指数(如chao1、shannon)?
A: Chao1:是用chao1 算法估计群落中含OTU 数目的指数,chao1 在生态学中常用来估计物种总数,由Chao (1984) 最早提出。Chao1值越大代表物种总数越多。
Schao1=Sobs+n1(n1-1)/2(n2+1)
其中Schao1为估计的OTU数,Sobs为观测到的OTU数,n1为只有一条序列的OTU数目,n2为只有两条序列的OTU数目。
Shannon:用来估算样品中微生物的多样性指数之一。它与 Simpson 多样性指数均为常用的反映 alpha 多样性的指数。Shannon值越大,说明群落多样性越高。
Ace:用来估计群落中含有OTU 数目的指数,由Chao 提出,是生态学中估计物种总数的常用指数之一,与Chao1 的算法不同。
Simpson:用来估算样品中微生物的多样性指数之一,由Edward HughSimpson ( 1949) 提出,在生态学中常用来定量的描述一个区域的生物多样性。Simpson 指数值越大,说明群落多样性越高。
辛普森多样性指数=随机取样的两个个体属于不同种的概率
=1-随机取样的两个个体属于同种的概率
 10/36
10/36Alpha多样性指数差异箱形图
分别对 Alpha diversity 的各个指数进行秩和检验分析(若两组样品比较则使用 R 中的wilcox.test 函数,若两组以上的样品比较则使用 R 中的 kruskal.test 函数),通过秩和检验筛选不同条件下的显著差异的 Alpha Diversity指数。
 11/36
11/36Beta多样性分析(样品间差异分析)
Beta多样性度量时空尺度上物种组成的变化,是生物多样性的重要组成部分,与许多生态学和进化生物学问题密切相关,因此在最近10年间成为生物多样性研究的热点问题之一。
12/36PCoA分析
PCoA(principal co-ordinates analysis)是一种研究数据相似性或差异性的可视化方法,通过一系列的特征值和特征向量进行排序后,选择主要排在前几位的特征值,PCoA 可以找到距离矩阵中最主要的坐标,结果是数据矩阵的一个旋转,它没有改变样品点之间的相互位置关系,只是改变了坐标系统。通过PCoA 可以观察个体或群体间的差异。
每一个点代表一个样本,相同颜色的点来自同一个分组,两点之间距离越近表明两者的群落构成差异越小。PCoA有多张图,分别代表的PCoA1-2,2-3,3-1。
 13/36
13/36NMDS分析(非度量多维尺度分析)
NMDS(Nonmetric Multidimensional Scaling)常用于比对样本组之间的差异,可以基于进化关系或数量距离矩阵。
横轴和纵轴:表示基于进化或者数量距离矩阵的数值 在二维表中成图。
与PCA分析的主要差异在于考量了进化上的信息。
每一个点代表一个样本,相同颜色的点来自同一个分组,两点之间距离越近表明两者的群落构成差异越小。
 14/36
14/36PCA分析
主成分分析PCA(Principal component analysis)是一种研究数据相似性或差异性的可视化方法,通过一系列的特征值和特征向量进行排序后,选择主要的前几位特征值,采取降维的思想,PCA 可以找到距离矩阵中最主要的坐标,结果是数据矩阵的一个旋转,它没有改变样品点之间的相互位置关系,只是改变了坐标系统。详细关于主成分分析的解释推荐大家看一篇文章,http://blog.csdn.net/aywhehe/article/details/5736659 。通过PCA 可以观察个体或群体间的差异。
每一个点代表一个样本,相同颜色的点来自同一个分组,两点之间距离越近表明两者的群落构成差异越小。
以上三个图可能遇到的问题:
1:PCA,PcoA,NMDS分析分别是基于什么数据画的?
回答:PCA,PcoA,NMDS分析均是基于OTU分类taxon数据所画,用的是R语言Vegan包中的相关函数画成,其中PcoA与NMDS还要基于样本之间的距离矩阵才能画成。
2:PCA分析如果图中大部分点集中在一起,少数点在很远的外围,是什么原因造成的?
回答:是因为样本OTU分类时候,少数样本某些菌含量特别高所造成,导致这些样本偏离正常范围,建议单独拿出这些样本观察,看是否是实验错误。
3:PCA分析时,不是有PC1,PC2,PC3三个坐标吗?是给出三张图吗?还是三维立体图?
回答:PCA作图时,会得出PC1,PC2,PC3三个坐标,可以根据PC12,PC13,PC23分别作图,一般给出的是PC12的图,当PC12图质量不好,看不出明显的样本分类效果时,可以看PC13或PC23的图分类是否清晰,也可以用R语言rgl包做出PC123三维图。
QIIME本身结果中有提供PCA的三维图结果,可以通过网页打开。
 15/36
15/36PCA,PcoA,NMDS分析都属于排序分析(Ordination analysis)。排序(ordination)的过程就是在一个可视化的低维空间或平面重新排列这些样本,使得样本之间的距离最大程度地反映出平面散点图内样本之间的关系信息。
1、只使用物种组成数据的排序称作非限制性排序(unconstrained ordination)(1)主成分分析(principal components analysis,PCA)(2)对应分析(correspondence analysis, CA)(3)去趋势对应分析(Detrended correspondence analysis, DCA)(3)主坐标分析(principal coordinate analysis, PCoA)(4)非度量多维尺度分析(non-metric multi-dimensional scaling, NMDS)
2、同时使用物种和环境因子组成数据的排序叫作限制性排序(constrained ordination)(1)冗余分析(redundancy analysis,RDA)(2)典范对应分析(canonical correspondence analysis, CCA)
比较PCA和PCoA:
在非限制性排序中,16S和宏基因组数据分析通常用到的是PCA分析和PCoA分析,两者的区别在于:PCA分析是基于原始的物种组成矩阵所做的排序分析,而PCoA分析则是基于由物种组成计算得到的距离矩阵得出的。在PCoA分析中,计算距离矩阵的方法有很多种,包括如:Euclidean, Bray-Curtis, and Jaccard,以及(un)weighted Unifrac (利用各样品序列间的进化信息来计算样品间距离,其中weighted考虑物种的丰度,unweighted没有对物种丰度进行加权处理)。
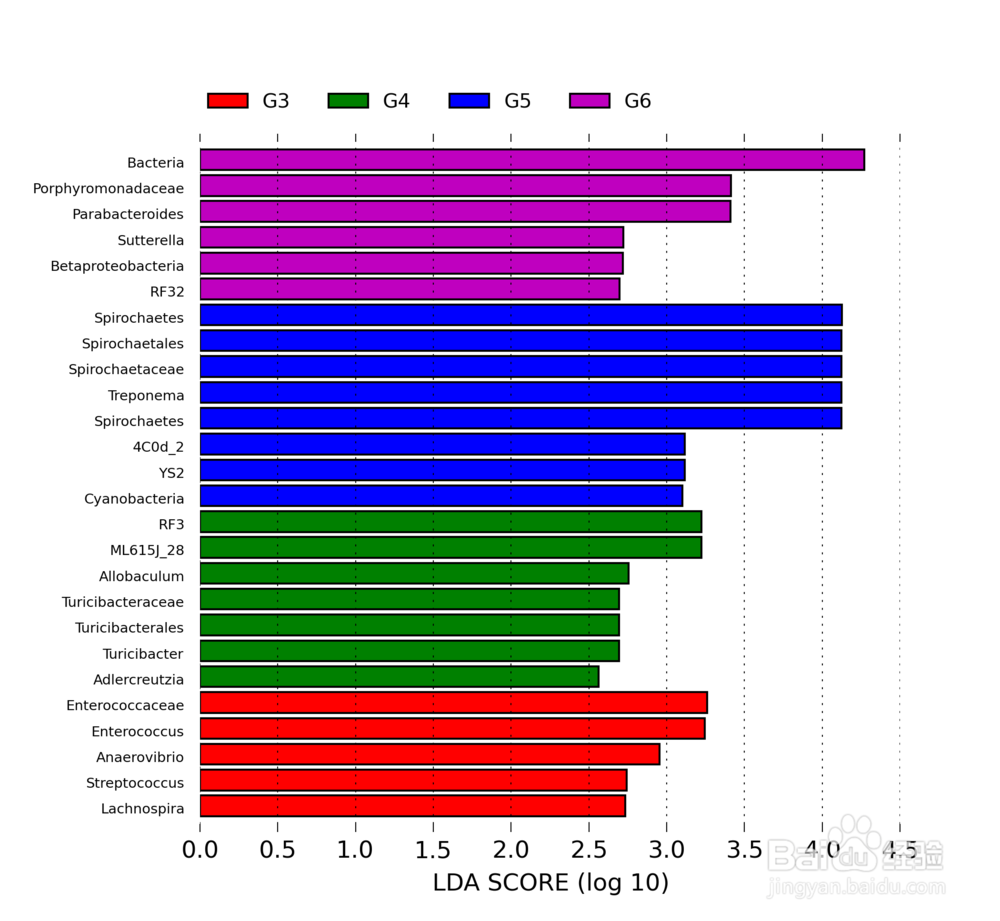
16/36LDA差异贡献分析
PCA和LDA的差别在于,PCA,它所作的只是将整组数据整体映射到最方便表示这组数据的坐标轴上,映射时没有利用任何数据内部的分类信息,是无监督的,而LDA是由监督的,增加了种属之间的信息关系后,结合显著性差异标准测试(克鲁斯卡尔-沃利斯检验和两两Wilcoxon测试)和线性判别分析的方法进行特征选择。除了可以检测重要特征,他还可以根据效应值进行功能特性排序,这些功能特性可以解释顶部的大部分生物学差异。详细说明可以参考这篇文章http://blog.csdn.net/sunmenggmail/article/details/8071502 。
不同颜色代表不同样本或组之间的显著差异物种。使用LefSe软件分析获得,其中显著差异的logarithmic LDA score设为2。
问题:LDA分析有什么用?
回答:组间差异显著物种又可以称作生物标记物(biomarkers),该分析主要是想找到组间在丰度上有显著差异的物种。
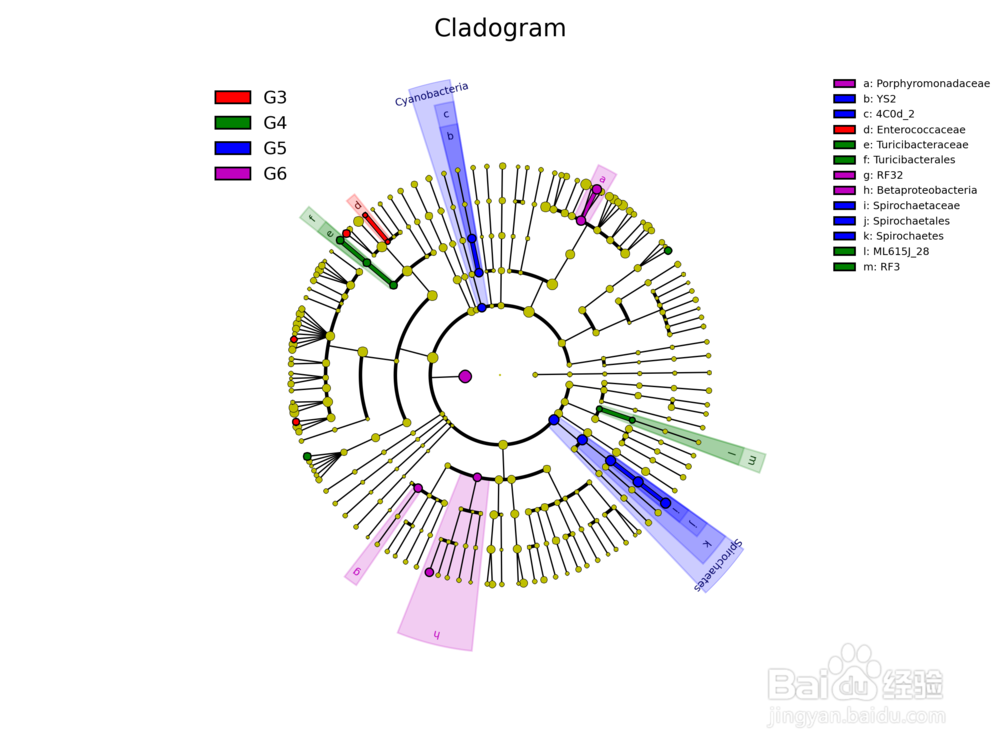
 17/36
17/36物种进化树的样本群落分布图
是将不同样本的群落构成及分布以物种分类树的形式在一个环图中展示。数据经过分析后,将物种分类树和分类丰度信息通过软件GraPhlAn(http://huttenhower.sph.harvard.edu/GraPhlAn )进行绘制。其目的是将物种之间的进化关系以及不同样本的物种分布丰度和最高分布样本的信息在一个视觉集中的环图中一次展示,其提供的信息量较其他图最为丰富。
中间为物种进化分类树,不同颜色的分支代表不同的纲(具体的代表颜色见右上角的图例),之后外圈的灰色标示字母的环表示的是本次研究中比例最高的15个科(字母代表的科参见左上角的图例)。之后的外圈提供的是热力图,如果样本数=10个则绘制样本,如果样本数超过10个则按照分组绘制,每一环为一个样本,根据其丰度绘制的热力图。最外圈为柱状图,绘制的是该属所占比例最高的样本的丰度和样本颜色(样本颜色见环最下方的样本名字的颜色)。其中热力图和柱状图取值均为原比例值x10000后进行log2转换后的值
参考文献:
1. Vazquez-Baeza Y, Pirrung M, Gonzalez A, Knight R. 2013. Emperor: A tool for visualizing high-throughput microbial community data. Gigascience 2(1):16.
2. Legendre, P. and Legendre, L. 1998. Numerical Ecology. Second English Edition. Developments in Environmental Modelling 20. Elsevier, Amsterdam.
3. Segata N, Izard J, Waldron L, et al. Metagenomic biomarker discovery and explanation. Genome Biol, 2011, 12(6): R60.
4. Langille MGI, Zaneveld J, Caporaso JG, McDonald D, Knights D, Reyes JA et al. (2013). Predictive functional profiling of microbial communities using 16S rRNA marker gene sequences. Nat Biotechnol 31: 814–821.
 18/36
18/36物种相关性分析
根据各个物种在各个样品中的丰度以及变化情况,计算物种之间的相关性,包括正相关和负相关。
相关性分析使用 CCREPE 算法,首先对原始 16s 测序数据的种属数量进行标准化,然后进行 Spearman 和 Pearson 秩相关分析并进行统计检验,计算出各个物种之间的相关性,之后在所有物种中根据 simscore 绝对值的大小,挑选出相关性最高的前 100 组数据,基于 Cytoscap 绘制共表达分析网络图,网络图采用两种不同的形式表现出来。
物种相关性网络图A:图中每一个点代表一个物种,存在相关性的物种用连线连接,其中,红色的连线代表负相关,绿色的先代表正相关,连线颜色的深浅代表相关性的高低。
物种相关性网络图B:图中每一个点代表一个物种,点的大小表示与其他物种的关联关系的多少,其中与之有相关性的物种数越多,点的半径和字体越大,连线的粗细代表两物种之间相关性的大小,连线越粗,相关性越高。
参考文献:
Schwager E, Weingart G, Bielski C, et al. CCREPE: Compositionality Corrected by Permutation and Renormalization. 2014.

 19/36
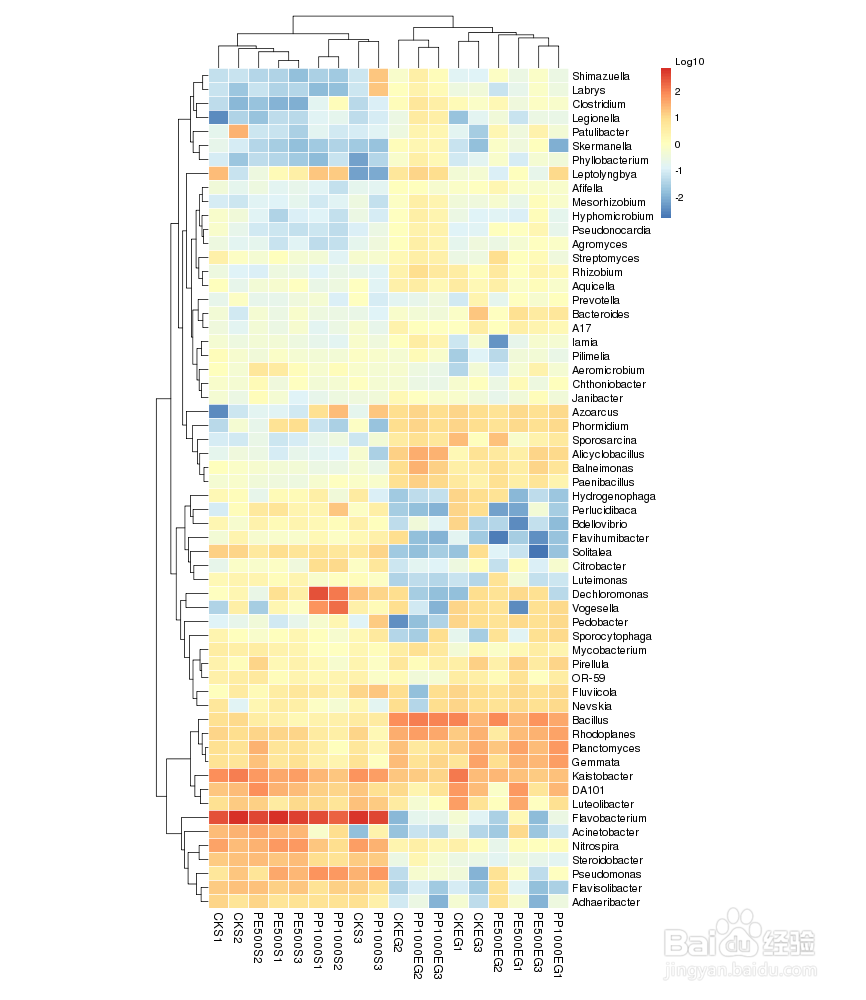
19/36聚类分析
根据OUT数据进行标准化处理(1wlog10)之后,选取数目最多的前60个物种,基于R heatmap进行作图,热图中的每一个色块代表一个样品的一个属的丰度,样品横向排列,属纵向排列,两个热图,差异是是否对样品进行聚类,从聚类中可以了解样品之间的相似性以及属水平上的群落构成相似性。
如果聚类结果中出现大面积的白或黑是因为大量的菌含量非常低,导致都没有数值,可以在绘制之前进行标准化操作,对每一类菌单独自身进行Z标准化。

 20/36
20/36组间菌群比较选取物种标志物
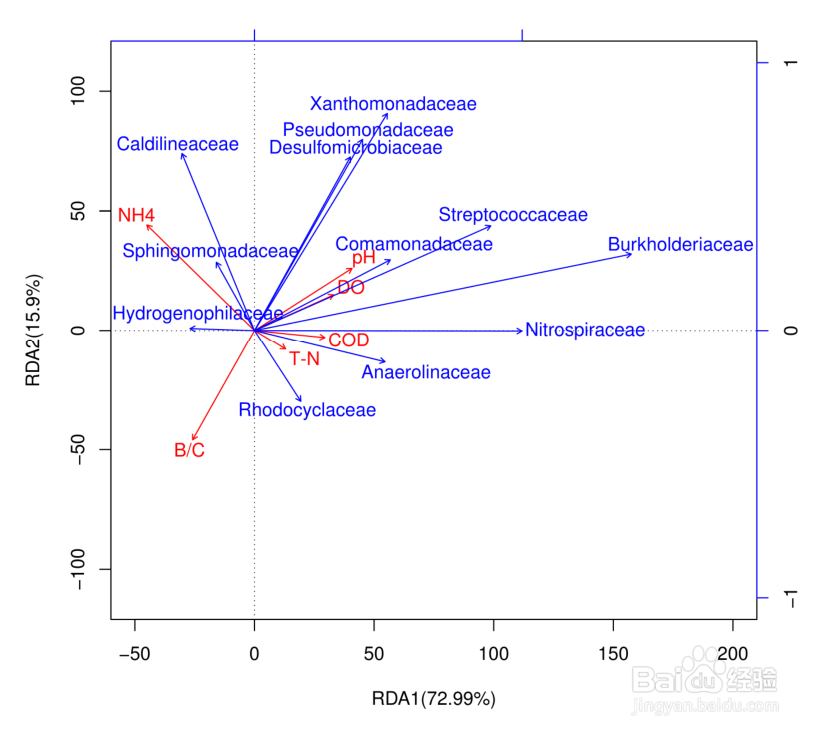
RDA分析
CCA/RDA分析基于对应分析发展的一种排序方法,将对应分析与多元回归分析相结合,每一步计算均与环境因子进行回归,又称多元直接梯度分析。主要用来反映菌群与环境因子之间的关系。
RDA 是基于线性模型,CCA是基于单峰模型。分析可以检测环境因子、样品、菌群三者之间的关系或者两两之间的关系。
冗余分析可以基于所有样品的OTU作图,也可以基于样品中优势物种作图;
箭头射线:箭头分别代表不同的环境因子;
夹角:环境因子之间的夹角为锐角时表示两个环境因子之间呈正相关关系,钝角时呈负相关关系。
环境因子的射线越长,说明该影响因子的影响程度越大; 不同颜色的点表示不同组别的样品或者同一组别不同时期的样品,图中的拉丁文代表物种名称,可以将关注的优势物种也纳入图中; 环境因子数量要少于样本数量,同时在分析时,需要提供环境因子的数据,比如 pH值,测定的温度值等。
 21/36
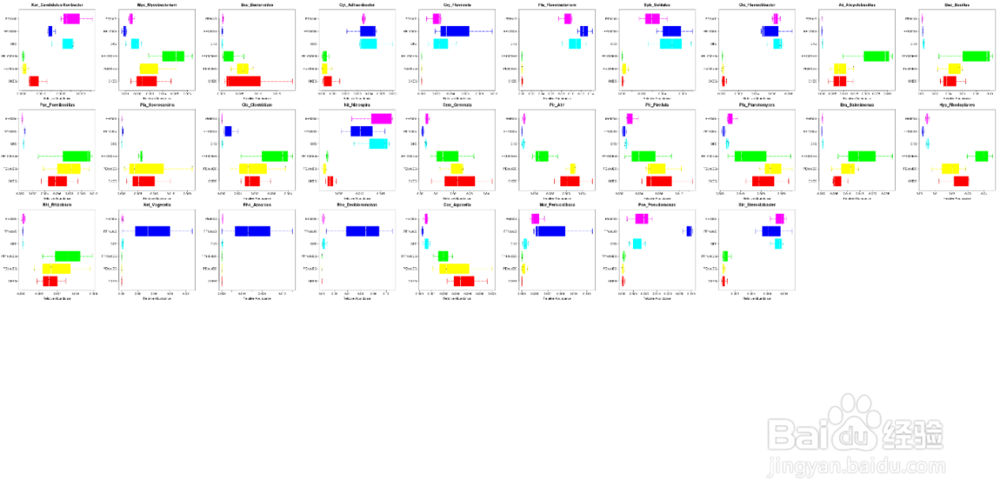
21/36组间菌群比较选取物种标志物
(属水平)组间物种差异性箱形图:
组间物种差异性盒形图描述在不同分组之间具有差异显著的某一物种做盒形图,图中以属水平为例做物种差异性盒形图。
图中不同颜色代表不同的分组,更直观显示组间物种差异。每一个盒形图代表一个物种,图上方是物种名。
 22/36
22/36组间菌群比较选取物种标志物
Anosim检验
Anosim分析是一种非参数检验,用来检验组间的差异是否显著大于组内差异,从而判断分组是否有意义。(做组间差异比较分析,分组内部至少要3个样本;若样本数不够或组间差异不明显则不生成该图)
R-value介于(-1,1)之间,R-value大于0,说明组间差异显著。R-value小于0,说明组内差异大于组间差异,统计分析的可信度用 P-value 表示,P 0.05 表示统计具有显著性。对Anosim的分析结果,基于两两样本之间的距离值排序获得的秩(组间的为between,组内的为within),这样任一两两组的比较可以获得三个分类的数据,并进行箱线图的展示(若两个箱的凹槽互不重叠,则表明它们的中位数有显著差异)
 23/36
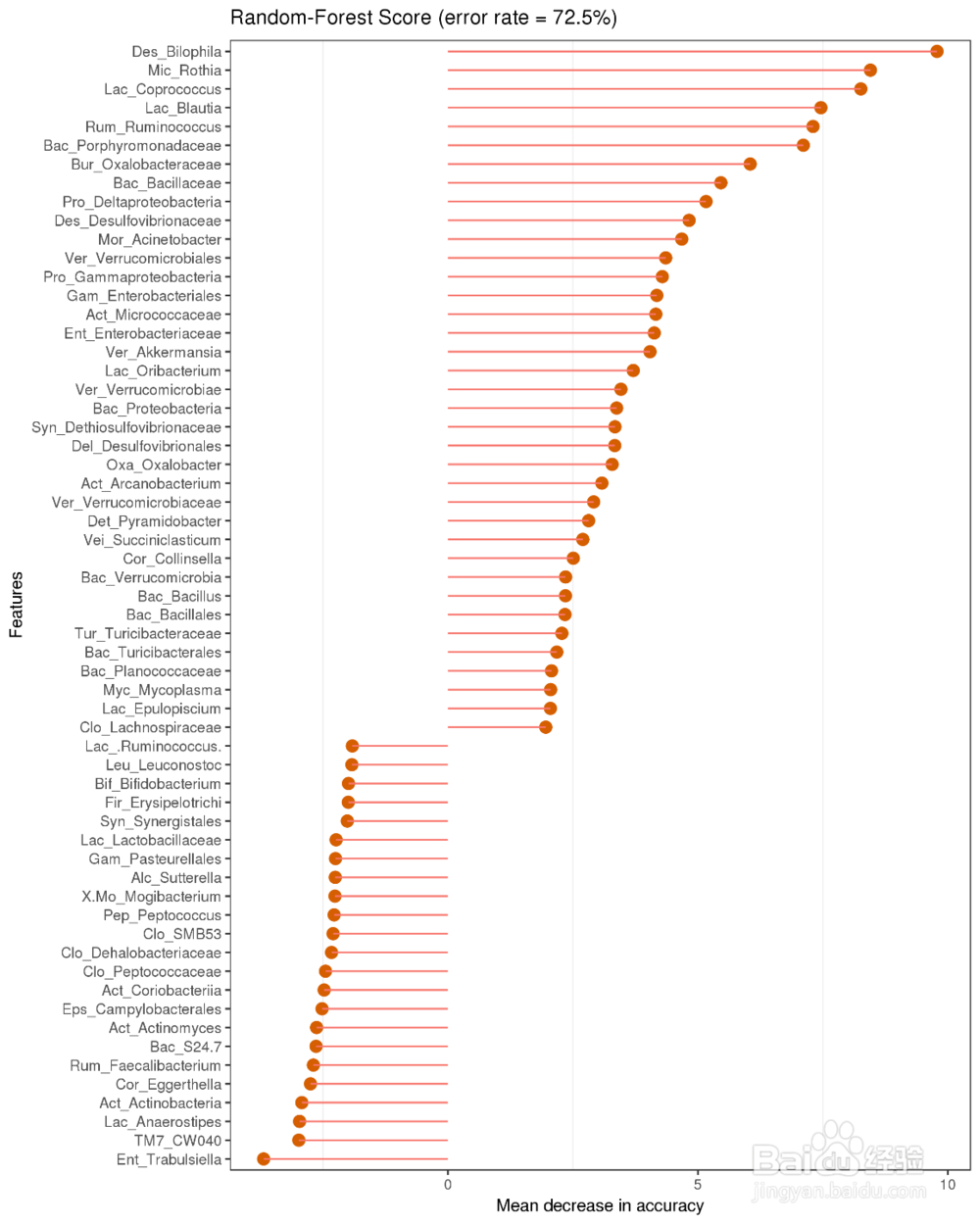
23/36组间菌群比较选取物种标志物
随机森林分类树属分类效果
随机森林是机器学习算法的一种,它可以被看作是一个包含多个决策树的分类器。其输出的分类结果是由每棵决策树“投票”的结果。由于每棵树在构建过程中都采用了随机变量和随机抽样的方法,因此随机森林的分类结果具有较高的准确度,并且不需要“减枝”来减少过拟合现象。随机森林可以有效的对分组样品进行分类和预测。
物种重要性点图。横坐标为重要性水平,纵坐标为按照重要性排序后的物种名称。上图反映了分类器中对分类效果起主要作用的菌属,按作用从大到小排列。
Error rate: 表示使用下方的特征进行随机森林方法预测分类的错误率,越高表示基于菌属特征分类准确度不高,可能分组之间菌属特征不明显。 图中以所有水平为例,取前60个作图。
 24/36
24/36组间菌群比较选取物种标志物
ROC曲线图
ROC 曲线指受试者工作特征曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,通过构图法揭示敏感性和特异性的相互关系。ROC 曲线将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。
 25/36
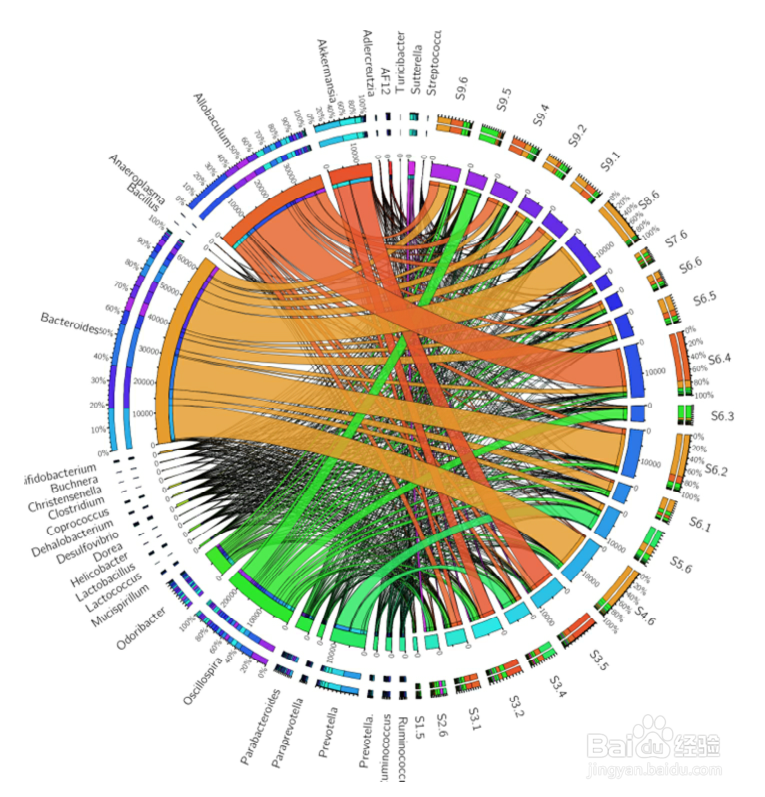
25/36组间菌群比较选取物种标志物
(属水平)样本-物种丰度关联circos弦装图
样本与物种的共线性关系 circus 图是一种描述样本与物种之间对应关系的可视化圈图,该图不仅反映了每个样本的优势物种组成比例,同时也反映了各优势物种在不同样本之间的分布比例。
样本与物种的共线性关系图,左半边表示样本属物种丰度情况。右半边表示属水平在不同样本中的分布比例情况。在最内一圈:左边不同颜色代表不同物种,宽度表示物种丰度,圈外数值表示物种丰度刻度值。一端连接右边的样本,不同颜色代表不同样本,条带端点宽度表示该样本中对应物种的比例分布。最外两圈:左边不同颜色表示不同样本在某一物种的比例,右边不同颜色表示不同物种在某一样本中的比例。
 26/36
26/36组间菌群比较选取物种标志物
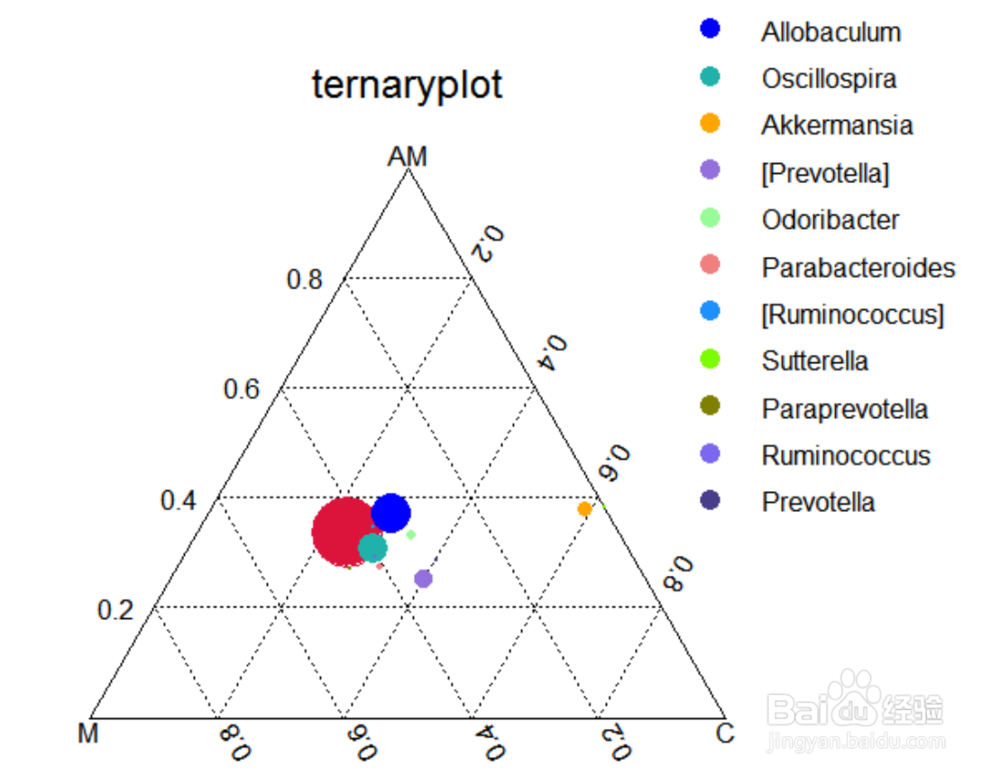
Ternary三元相图
三元相图是重心图的一种,它有三个变量,在一个等边三角形坐标系中,图中某一点的位置代表三个变量间的比例关系。这里表示三组样本之间优势物种的差异,通过三元图可以展示出不同物种在分组中的比重关系。
三角分别代表三个或三组样本,图中的圆分别代表排名最高哦的属水平的物种,三种颜色分别代表三组不同分组的优势物种,圆圈大小代表物种的相对丰度,圆圈理哪个顶点接近,表示此物种在这个分组中的含量较高。该分析仅限三个样本或三组样本之间分析比较。
 27/36
27/36组间菌群比较选取物种标志物
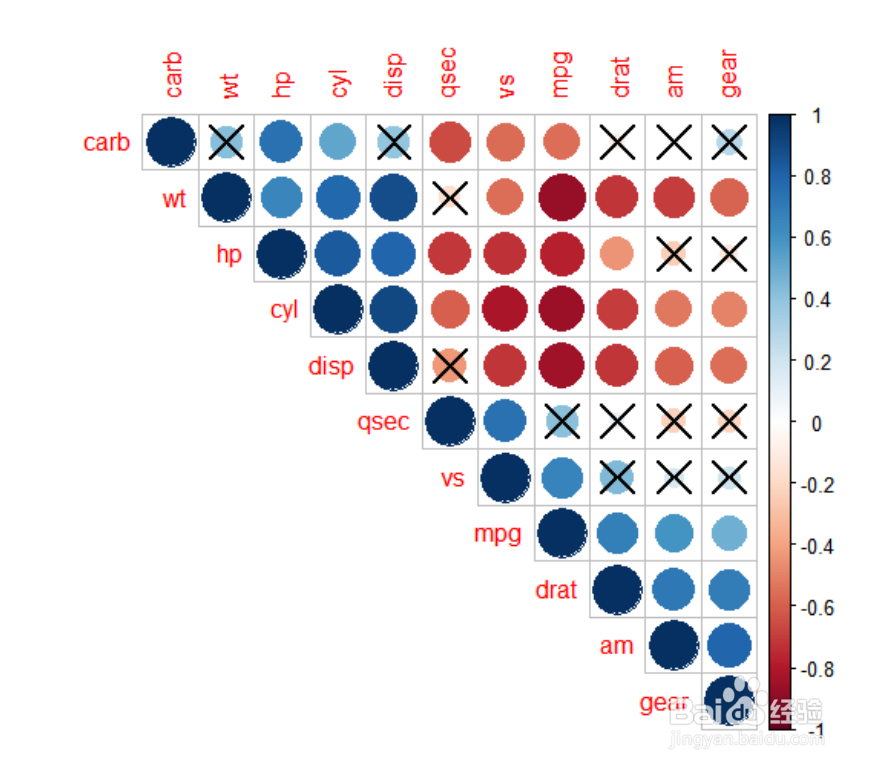
相关系数图
通过 R 软件的 corrplot 包绘制spearman 相关性热图,并通过该热图可以发现优势物种/样本之间重要的模式与关系。
蓝色系的为正相关,红色系的为负相关,×表示检验水平下无意义。越靠近颜色条两头,相关系数越大。所以说,我们可以通过实心圆的颜色和大小判断相关的方向和相关系数的大小。
 28/36
28/36组间菌群比较选取物种标志物
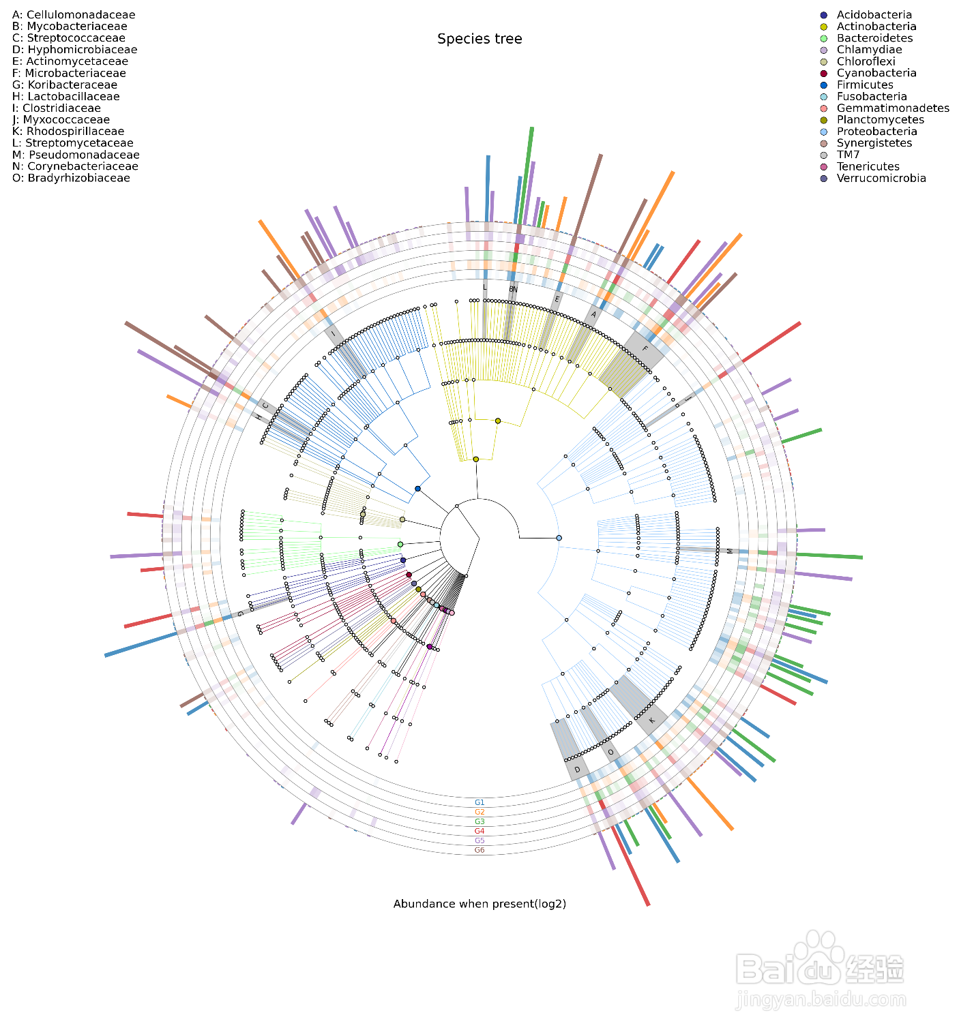
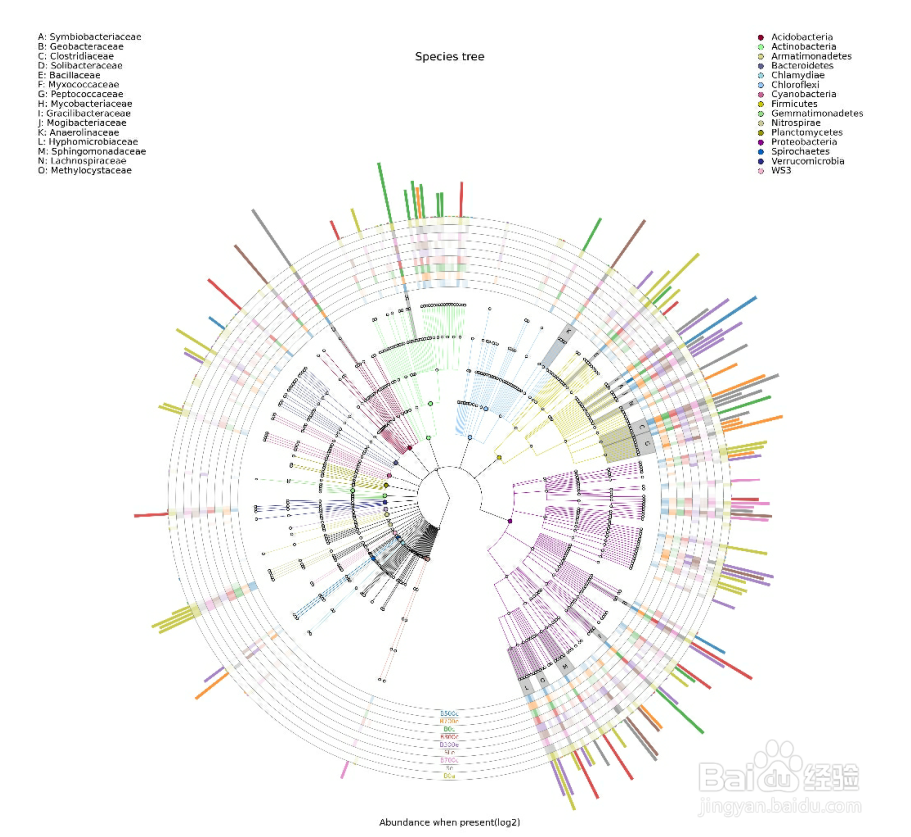
GraPhlan 图
物种进化树的样本群落分布图 GraPhlan 图是将不同样本的群落结构及分布以物种分类树的形式在一个环图中展示。
使用 GraPhlan 结合 OTU Table对一个分组所有样本的 OTU 物种注释结果进行总体展示,便于看出优势菌种。
其目的是将物种之间的进化关系以及不同样本的物种分布丰度和最高分布样本的信息在一个视觉集中在换图中展示,提供的信息量较其他图更丰富。
图中中间为物种进化分类树,不同颜色的分支代表不同的纲(具体的代表颜色见右上角的图例),之后外圈的灰色标示字母的环表示的是本次研究中比例最高的 15 个科(字母代表的科参见左上角的图例)。之后的外圈提供的是热力图,如果样本数 =10 个则绘制样本,如果样本数超过 10 个则按照分组绘制,每一环为一个样本,根据其丰度绘制的热力图。最外圈为柱状图,绘制的是该属所占比例最高的样本的丰度和样本颜色(样本颜色见环最下方的样本名字的颜色)。其中热力图和柱状图取值均为原比例值 x10000后进行 log2 转换后的值。
 29/36
29/36菌群代谢功能预测
通过 16S/ITS 多样性测序可以准确知道群落的物种结构,但越来越多的研究表明,微生物的群落功能组成比物种组成与环境关系更为密切。基于 16S/ITS 的测序结果进行功能预测的方法有 PICRUSt、Tax4Fun、FAPROTAX及BugBase
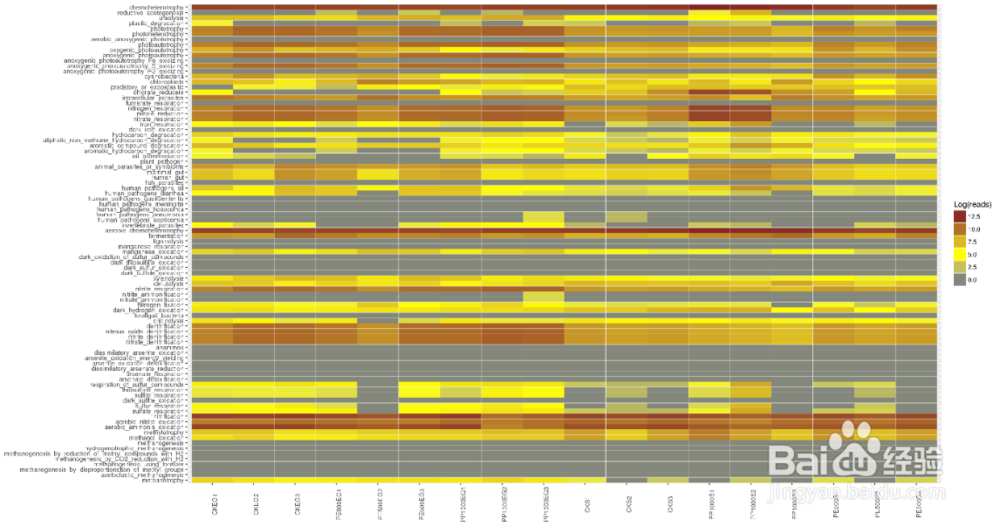
FAPROTAX生态功能预测
FAPROTAX是一款在2016年发表在SCIENCE上的较新的基于16S测序的功能预测软件。它整合了多个已发表的可培养菌文章的原核功能数据库,数据库包含超过4600个物种的7600多个功能注释信息,这些信息共分为nitraterespiration,methanogenesis, fermentation 和plant pathogenesis等80多个功能分组。
FAPROTAX是基于目前对可培养菌的文献资料手动整理的原核功能注释数据库,其包含了收集自4600多个原核微生物的80多个功能分组(如硝酸盐呼吸、产甲烷、发酵、植物病原等)的7600多条功能注释信息。
如果PICRUSt在肠道微生物研究更为适合,那么FAPROTAX尤其适用于生态环境研究,特别是地球化学物质循环分析。FAPROTAX适用于对环境样本(如海洋、湖泊等)的生物地球化学循环过程(特别是碳、氢、氮、磷、硫等元素循环)进行功能注释预测。因其基于已发表验证的可培养菌文献,其预测准确度可能较好,但相比于上述PICRUSt和Tax4Fun来说预测的覆盖度可能会降低。
参考文献: Louca, S., Parfrey, L. W. Doebeli, M. Decoupling function and taxonomy in the global ocean microbiome. Science 353, 1272–1277(2016).
FAPROTAX可根据16S序列的分类注释结果对微生物群落功能(特别是生物地化循环相关)进行注释预测。图中横坐标代表样本,纵坐标表示包括碳、氢、氮、硫等元素循环相关及其他诸多功能分组。 可快速用于评估样品来源或特征。
 30/36
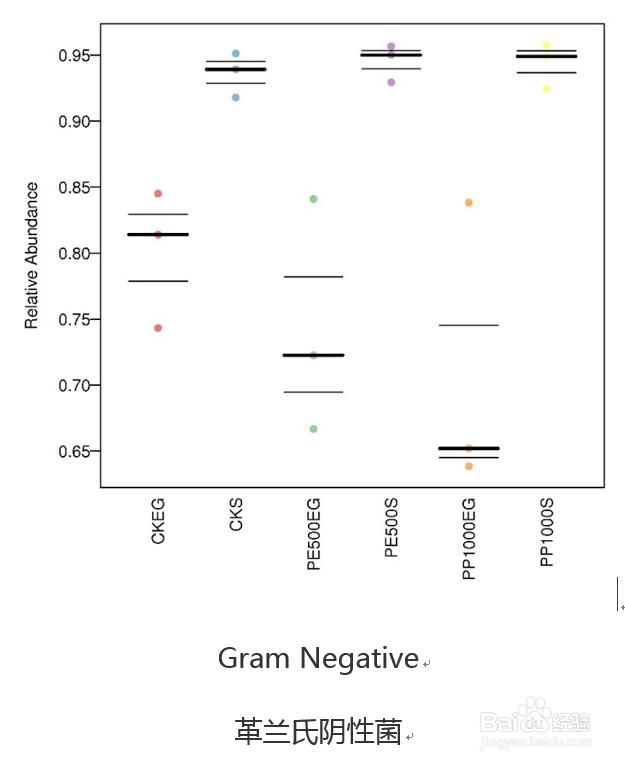
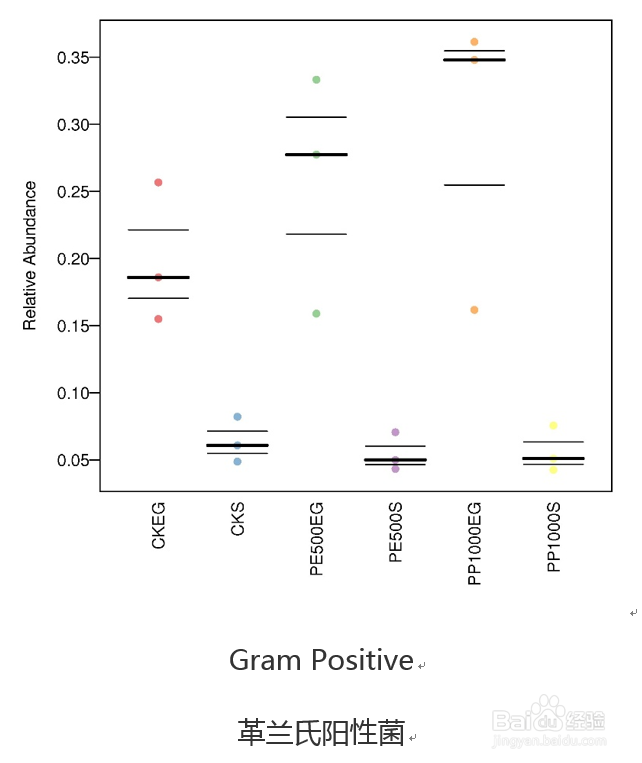
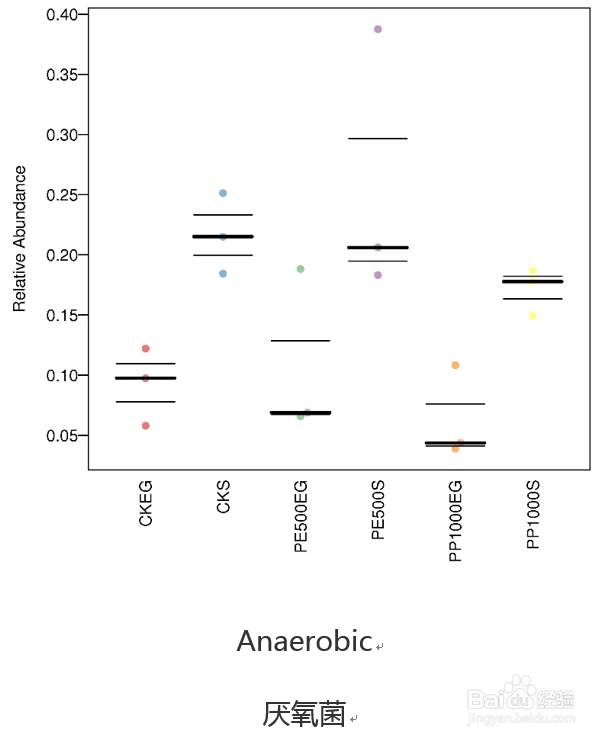
30/36基于BugBase的表型分类比较
Bugbase也是16年所提供服务的一款免费在线16S功能预测工具,到今年才发表文章公布其软件原理。该工具主要进行表型预测,其中表型类型包括革兰氏阳性、革兰氏阴性、生物膜形成、致病性、移动元件、氧需求,包括厌氧菌、好氧菌、兼性菌)及氧化胁迫耐受等7类
参考文献:Thomas A M, Jesus E C, Lopes A, et al. Tissue-associated bacterial alterations in rectal carcinoma patients revealed by 16S rRNA community profiling. Frontiers in Cellular and Infection Microbiology, 2016, 6.
 31/36
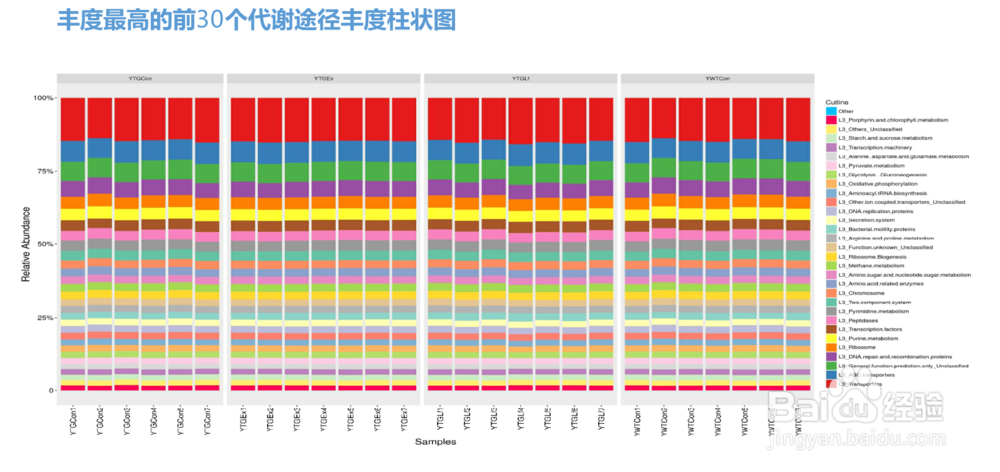
31/36Picrust群落功能差异分析
通过对已有测序微生物基因组的基因功能的构成进行分析后,我们可以通过16s测序获得的物种构成推测样本中的功能基因的构成,从而分析不同样本和分组之间在功能上的差异(PICRUSt Nature Biotechnology, 1-10. 8 2013)。
通过对宏基因组测序数据功能分析和对应16s预测功能分析结果的比较发现,此方法的准确性在84%-95%,对肠道微生物菌群和土壤菌群的功能分析接近95%,能非常好的反映样品中的功能基因构成。
为了能够通过16s测序数据来准确的预测出功能构成,首先需要对原始16s测序数据的种属数量进行标准化,因为不同的种属菌包含的16s拷贝数不相同。然后将16s的种属构成信息通过构建好的已测序基因组的种属功能基因构成表映射获得预测的功能结果。(根据属这个水平,对不同样本间的物种丰度进行显著性差异两两检验,我们这里的检验方法使用STAMP中的two-sample中T-TEST方法,Pvalue值过滤为0.05,作Extent error bar图。)
此处提供COG,KO基因预测以及KEGG代谢途径预测。用户也可自行使用我们提供的文件和软件(STAMP)对不同层级以及不同分组之间进行统计分析和制图,以及选择不同的统计方法和显著性水平。
参考文献:
Donovan H. Parks1 ,Gene W. Tyson,STAMP: statistical analysis of taxonomic and functional profiles, Bioinformatics(2014)30(21):3123-3124.doi:10.1093
 32/36
32/36COG构成差异分析图
图中不同颜色代表不同的分组,列出了COG构成在组间存在显著差异的功能分类以及在各组的比例,此外右侧还给出了差异的比例和置信区间以及P-value。
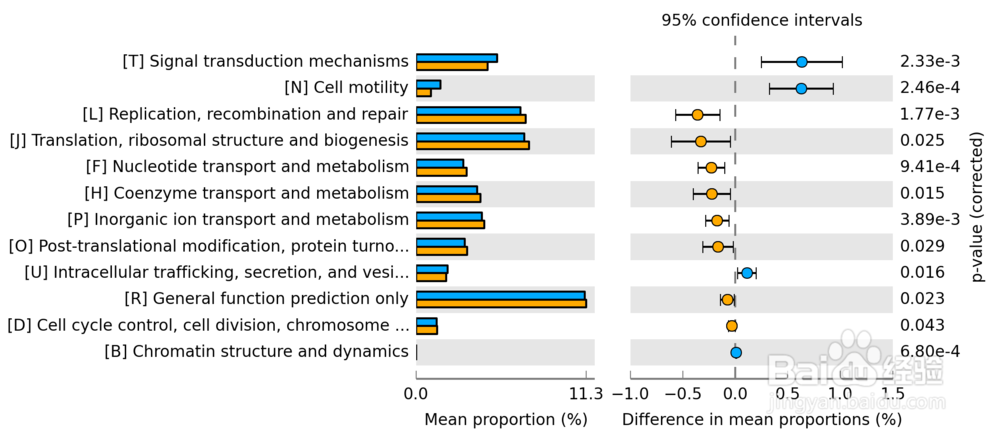 33/36
33/36KEGG代谢途径差异分析图
通过KEGG代谢途径的预测差异分析,我们可以了解到不同分组的样品之间在微生物群落的功能基因在代谢途径上的差异,以及变化的高低。为我们了解群落样本的环境适应变化的代谢过程提供一种简便快捷的方法。
图解读:图中不同颜色代表不同的分组,列出了在第三层级的构成在组间存在显著差异的KEGG代谢途径第三层分类以及在各组的比例,此外右侧还给出了差异的比例和置信区间以及P-value。
本例图所显示的是第三层级的KEGG代谢途径的差异分析,也可以针对第二或第一层的分级进行分析。
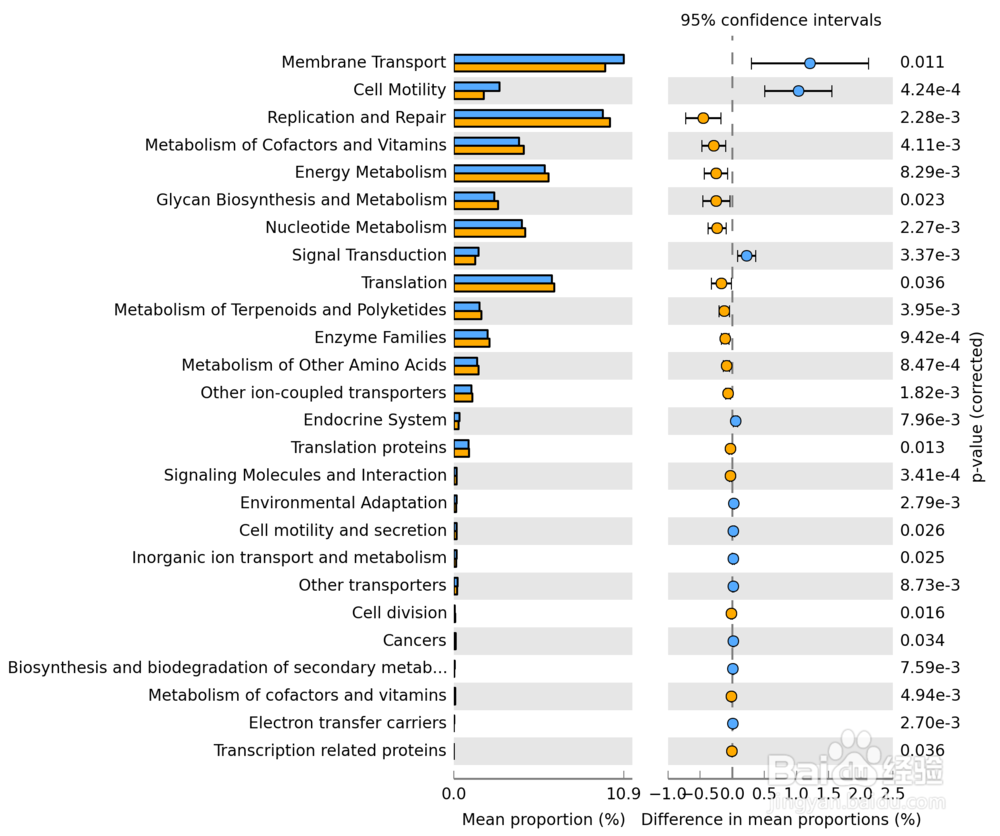 34/36
34/36基因的差异分析图
除了能对大的基因功能分类和代谢途径进行预测外,我们还能提供精细的功能基因的数量和构成的预测,以及进行样本间以及组间的差异分析,并给出具有统计意义和置信区间的分析结果。
这一分析将我们对于样本群落的差异进一步深入到了每一类基因的层面。
图解读:图中不同颜色代表不同的分组,列出了在组间/样本间存在显著差异的每一个功能基因(酶)以及在各组的比例,此外右侧还给出了差异的比例和置信区间以及P-value。
 35/36
35/36在获得标准报告后如果希望单独修改分组或对某些组之间进行显著性差异分析,可以使用STAMP软件在自己的电脑上进行数据分析。STAMP提供了丰富的统计检验方法和图形化结果的输出。
在使用STAMP之前需要首先准备需要的spf格式文件和样品分组信息表。在我们的报告中已经将KEGG和KO以及COG的结果文件后经过转换生成了适用于STAMP软件打开的spf格式文件,还有对应的分组信息表文件groupfile.txt。
以下是使用STAMP时的一些相关问题,详细的STAMP使用教程可以参考我们提供的STAMP使用教程。
1、 stamp作图用的原始数据的来源?
STAMP 可以直接使用来自QIIME的biom文件和PICUST的KEGG和ko 文件,groupfile.txt文件的格式为tab-saperated value (tab键隔开的数据)
2、 分组问题:导入数据之后,viewàgroup legend ,在窗口右侧会出现分组栏,根据需要进行分组。
3、 Unclassiffied选项中,remain Unclassiffied reads、remove Unclassiffied reads、和use only for calculating frequency profiles 方法的区别?
remain Unclassiffied reads和use only for calculating frequency profiles方法会保留所有的数据,而remove Unclassiffied reads仅仅保留有确定分组信息的数据。
4、 Statistical test 中,Welch’s t-test、t-test、white’s non-parametric t-test的区别,各自优缺点?
为了确保统计学意义和准确度和精确性,需要足够多的样本数目,t-test检验可以在最少样本数为4的时候确保高的准确度和精确性。
当两个样本之间具有相同方差的时候,用t-test更为准确,当两个样本没有相同方差,Welch’s t-test更为准确。
当样本数目少于8的时候,可以使用white’s non-parametric t-test,该计算时间较长,当样本数目过多的时候不宜使用该方法。
5、 Two-group 中type: one side 和 two side 的区别?
One side 只会显示前一个group与后一个group差异的比例,而two side 两者之间的比例均会显示。
6、 STAMP在使用时首先打开了一个分析文件,如果新打开一个可能会导致显示错误?
目前版本的STAMP存在一些小问题,一次分析只能使用一个数据文件,如果要打开新的需要关闭软件后再打开。
36/36有其他问题可以联系谷禾信息。
注意事项假设您要对人体肠道微生物菌群进行测序,一般可以选择对粪便进行取样。一般建议采取新鲜样品,因为微生物本身是活的群体,样品长期保存或不在原环境下保存会改变原有菌群的构成,最终导致我们得到的菌群构成发生偏差。比如粪便样品如果4度低温保存了一段时间,则其中部分耐低温的菌可能仍然在持续繁殖,这样最终样品的菌群会发生偏差。如果是送往公司测序也建议首先对样品进行DNA提取后再寄送,因为原始样品的寄送过程也可能导致菌群变化。
生物版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_685775.html