 订阅
订阅利用arcgis进行多距离空间聚类分析
来源:网络收集 点击: 时间:2024-05-11工具输出是一个包含以下字段的表:ExpectedK和ObservedK分别包含 K 预期值和 K 观测值。由于应用了L(d) 变换,因此 ExpectedK 值始终与距离值相匹配。DiffK字段包含 K 观测值与 K 预期值的差值。如果指定了置信区间选项,则附加字段LwConfEnv和HiConfEnv也将包含在输出表中。这些字段包含工具的每个迭代(由距离段数量参数指定)的置信区间信息。K 函数还可以创建图层汇总结果。
如果特定距离的 K 观测值大于 K 预期值,则与该距离(分析尺度)的随机分布相比,该分布的聚类程度更高。如果 K 观测值小于 K 预期值,则与该距离的随机分布相比,该分布的离散程度更高。如果 K 观测值大于 HiConfEnv 值,则该距离的空间聚类具有统计显著性。如果 K 观测值小于 LwConfEnv 值,则该距离的空间离散具有统计显著性。
2/7启用以图形方式显示结果参数可以创建汇总工具结果的折线图。预期结果以蓝线表示,而观测结果则以红线表示。观测线在预期线之上表明数据集在该距离内表现为聚类。观测线在预期线之下表明数据集在该距离内表现为离散。折线图以图层方式创建。这些图层是临时图层,会在关闭 ArcMap 时被删除。如果您右键单击该图层并选择保存,则该图表会被写入到“图表文件”。如果在保存图表后保存地图文档,则此图表文件的链接会通过 .mxd 保存。对于线和面要素,距离计算中会使用要素的质心。对于多点、折线或由多部件组成的面,将会使用所有要素部件的加权平均中心来计算质心。点要素的加权项是 1,线要素的加权项是长度,而面要素的加权项是面积。
3/7下面将介绍如何计算置信区间:
无权重字段
如果未指定权重字段,则可通过在研究区域中随机分布点并计算该分布的L(d)来构建置信区间。点的每个随机分布称为一个“排列”。例如,如果选择了99 次排列,则在每次迭代时,该工具均会将一组点随机分布 99 次。将这些点分布 99 次之后,该工具会对每个距离选择相对 k 观察值向上和向下偏离最大的 k 值;这些值将成为置信区间。
包含一个权重字段
指定权重字段时,仅会对权重值进行随机重新分配来计算置信区间。点位置则保持固定。其实,指定“权重字段”时,位置会保持固定,并且该工具会评估空间中要素值的聚类。但如果未指定“权重字段”,则工具将分析要素位置的聚类/离散。
因为置信区间通过随机排列构建,所以定义置信区间的值将随着不同的随机排列而改变,甚至当参数相同时也是如此。但是,对于随机数生成器地理处理环境来说,如果设置一个种子值,重复分析将产生一致的结果。
为计算置信区间参数选择的排列数可以不受限制地转换为置信度:9 表示 90%,99 表示 99%,999 表示 99.9%。
如果未指定研究区域,此工具会使用最小外接矩形作为研究区域多边形。与范围不同,最小外接矩形不一定必须与 x 轴和 y 轴对齐。
K 函数统计对研究区域的大小非常敏感。视点所在研究区域大小的不同,相同排列点可以表现为聚类或离散。因此,认真考虑研究区域的边界非常有必要。下图是关于相同要素分布如何根据指定的研究区域进行分散或聚类的一个典型示例。
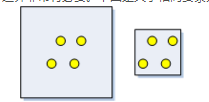 4/7
4/7如果研究区域方法参数选择了USER_PROVIDED_STUDY_AREA_FEATURE_CLASS,则研究区域要素类为必填项。
如果指定了研究区域要素类,则应只具有一个单部分要素(研究区域多边形)。
如果未指定开始距离或距离增量,则将基于输入要素类的范围计算默认值。
K 函数对位于研究区域边界附近的要素具有统计缺漏偏差。边界校正方法参数提供了解决这一偏差的方法。
NONE
不应用任何特定的边界校正。但是,落在用户指定的研究区域外的输入要素类中的点在相邻点计数中使用。如果您已从超大研究区域中收集数据但仅需分析数据集合边界内更小的区域,则此方法很适用。
SIMULATE_OUTER_BOUNDARY_VALUES
此方法在研究区域边界外创建边界内所发现点的镜像点,以便校正边附近的低估现象。将镜像与研究区域的边的最大距离范围相等的距离内的点。使用已镜像的点会使边点的相邻点估计更加精确。下图说明哪些点用于计算以及哪些点仅用于边校正。
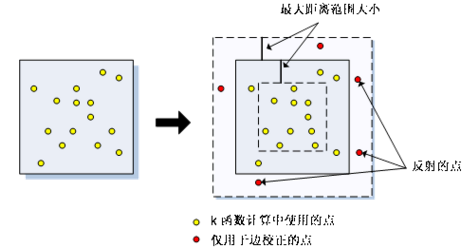 5/7
5/7REDUCE_ANALYSIS_AREA
此边校正技术将分析区域的大小收缩一定的距离,此距离与将在分析中使用的最大距离范围相等。收缩研究区域后,仅在为仍处于研究区域内的点评估相邻点数目时,才会考虑新研究区域外发现的点。K 函数计算期间,不会以任何其他方式使用这些点。下图说明哪些点用于计算以及哪些点仅用于边校正。
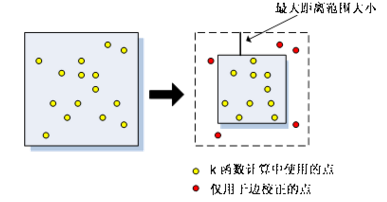 6/7
6/7RIPLEYS_EDGE_CORRECTION_FORMULA
此方法检查每个点与研究区域的边的距离以及这个点到其各相邻点的距离。如果有的相邻点与所涉及点的距离比与研究区域的边的距离更远,则所有这类相邻点都将被指定额外权重。此边校正方法仅适用于形状为正方形或矩形的研究区域,或者当为研究区域方法参数选择MINIMUM_ENCLOSING_RECTANGLE时才适用。
如果未应用边界校正,则统计缺漏偏差会随分析距离的增加而增加。如果启用以图形方式显示结果参数,您将注意到 ObservedK 线会在距离较大时下降。
从数学上说,“多距离空间聚类分析”工具使用 Ripleys k 函数的常用变换,其中带有随机点集的预期结果与输入距离相等。变换 L(d) 显示如下。
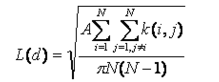 7/7
7/7其中 A 表示区域,N 表示点数,d 表示距离而 k(i, j) 表示权重。当 i 和 j 之间的距离小于或等于 d 时,权重为(如果无边界校正)1。当 i 和 j 之间的距离大于 d 时,权重为 0。应用边校正后,k(i,j) 的权重略有变化。
地图图层可用于定义输入要素类。在使用带有选择内容的图层时,分析只会包括所选的要素。
软件版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_738857.html