 订阅
订阅招聘数据采集:最简单,最好用,爬一爬采集器
来源:网络收集 点击: 时间:2024-05-14【导读】:
以拉勾网为例,采集上海地区最新职位的招聘信息,感兴趣的也可自己下载插件,采集智联招聘、58招聘等各大招聘网站数据。采集步骤类似。工具/原料more爬一爬数据采集器方法/步骤1/9分步阅读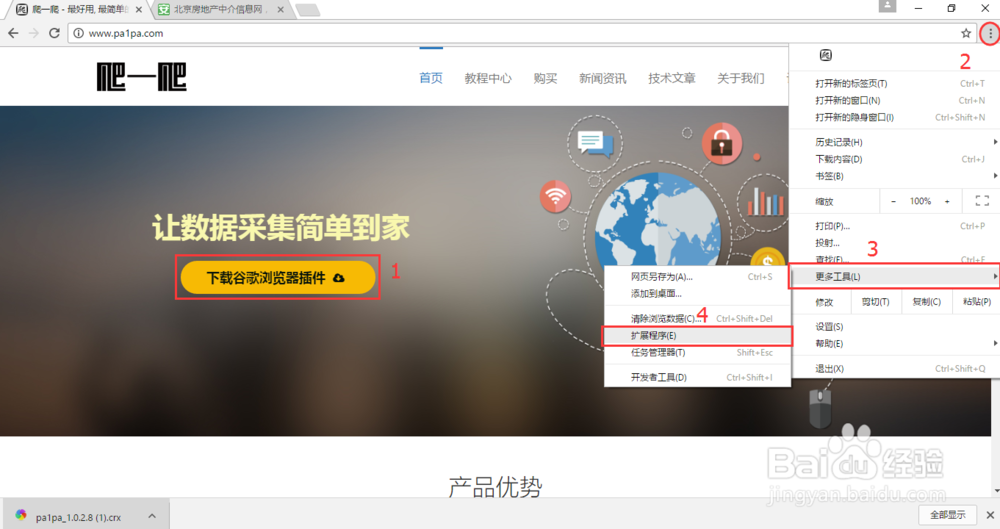
 2/9
2/9 3/9
3/9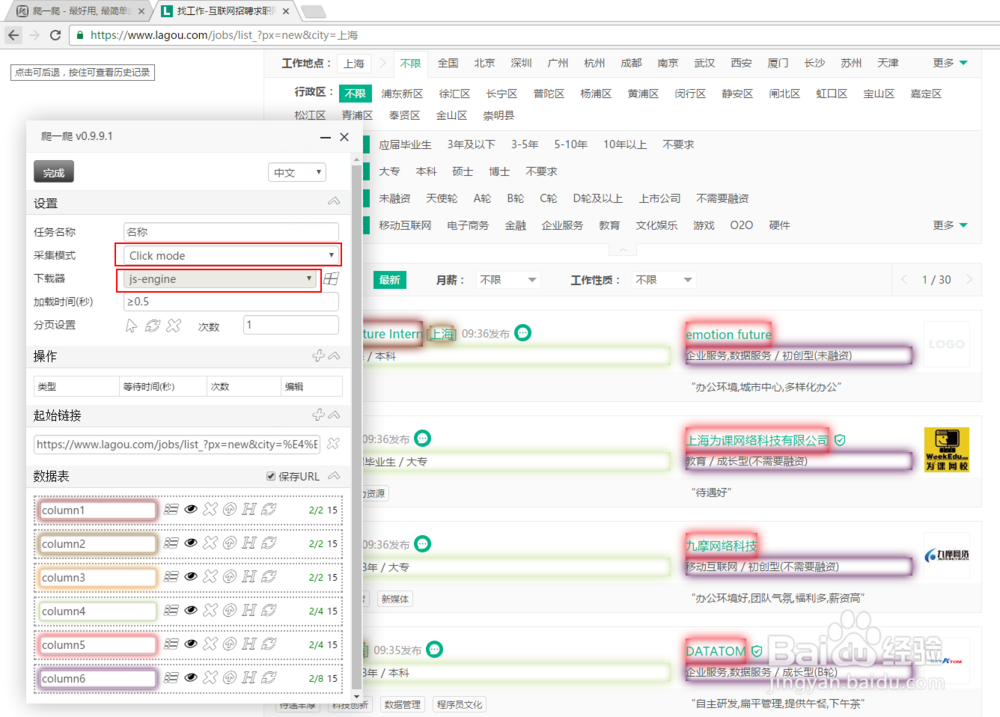 4/9
4/9 5/9
5/9 6/9
6/9
在谷歌浏览器中打开官网(pa1pa),下载浏览器插件,并如下步骤安装。
2/9安装成功后,在浏览器点击插件栏上便会出现”爬”的图标,注册登录即可使用爬一爬数据采集器。
3/9打开想要采集的网站,点击浏览器插件栏的”爬”的图标,启动插件。依次点击选取所要抓取的元素。如果色彩框没有包含所有的任务数据, 点击切换按钮,切换算法,直到选中所有的任务数据。(#注:本例的采集模式为Click Mode)
4/9如果要抓取多页信息,按照下图所示,点击分页设置的箭头后,选中“下一页”,并设置点击的次数。(#注:Click mode 在”分页设置”选择时候区别于Auto Mode,只选中“下一页”的按钮即可,非全部页码区域。)
5/9确认色彩框选中全部数据后,先点击“完成”按钮,再点击“测试”按钮,测试所采集的数据是否就是您想要的。
6/9确认测试成功后,点击”OK”按钮关闭测试窗口。填写任务名称(长度为4-32的字符,必填),并根据个人需要修改列名。
7/9点击“提交”按钮,任务创建成功。您可在官网的该任务的任务总览页面下运行并管理该任务。
8/9任务运行结束后,在页面的“数据”选项即可查看并下载完整数据。
9/9如果想获得本例采集的数据,可在官网论坛页面的数据中心下载或关注我索要即可。
注意事项如果数据出现采集不全的情况,建议吧加载时间设置长一点,频率设置大一点。
采集多页时候,多数网站均可用Auto Mode模式,下载器为http
如果解析为空,下载器更换为js-engine
版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_761365.html
上一篇:电脑钉钉直播没有声音怎么设置
下一篇:新东方厨师学校学完是什么学历