 订阅
订阅提取html书签中的标题和网址超链接
来源:网络收集 点击: 时间:2024-07-27我固执的相信有人不会导出html书签,所以再演示下大家看看。(绝不是为了凑篇幅)
打开IE浏览器,点击五角星/点击向下箭头/导入和导出。
 2/5
2/5依次点击:导出到文件/下一步。
 3/5
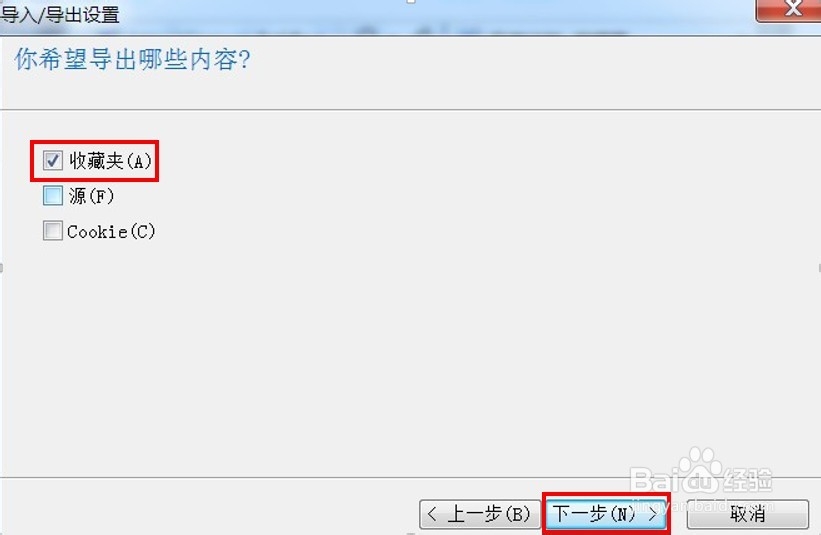
3/5选择收藏夹,下一步。
 4/5
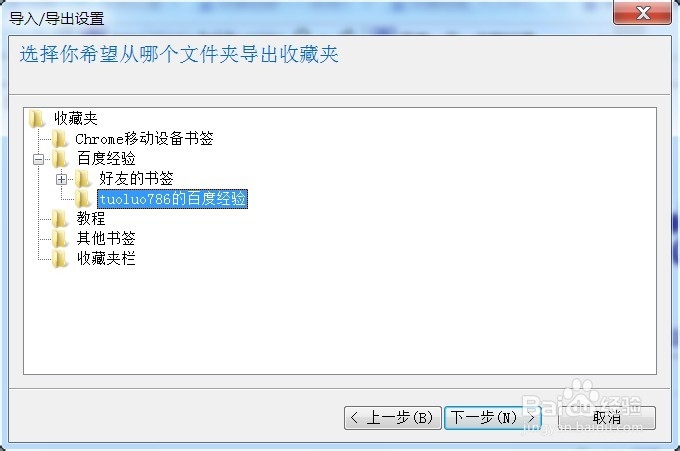
4/5选择你要导出的书签文件,点击下一步。IE浏览器的优点就在于此,可以很精确的单独导出特定文件夹的书签。
 5/5
5/5点击“浏览”选择你要导出书签文件的路径(记得给书签文件重命名下,方便查找,否则导出的文件默认是以bookmarks.html命名),点击导出。
 txt文本编辑器华丽登场1/3
txt文本编辑器华丽登场1/3其实我一直在思考,这个html书签你双击打开的时候在ie上是能看见标题的,并且这些标题文本都是可以复制的,但是就是不能看见链接!
 2/3
2/3既然能看见书签标题,那书签标题就一定存在这个html文件中,基于这个思维,那保存文本最小的文件莫过txt文档,恍然大悟,把其后缀名改为txt会是神马情况?
 3/3
3/3尼玛,原来网址和书签标题都在里面!不过看起来有点乱,但是这难不倒喜欢折腾的我。仔细观察发现网址和标题的前后都有特定的字符!这太熟悉了!
 还是要借助万能的、无比强大的excel1/8
还是要借助万能的、无比强大的excel1/8新建一个excel工作簿,快捷键ctrl+a/ctrl+c/ctrl+v组合使用,复制粘贴所有文本到excel中。
 2/8
2/8我们删除第一列发现所有数据都被删除,说明我们的数据都在第一列。那选中第一列,现在开始使用excel的数据分列功能。
 3/8
3/8选择分隔符号,下一步。
 4/8
4/8我们观察在网址的前后都有个符号,那我们先选择这个符号作为分割符,点击下一步。
 5/8
5/8预览发现黑色部分其实已经被分割到其它列,点击完成。
 6/8
6/8删除A列,A列已经不是我们需要的信息。
 7/8
7/8调整列宽,是文本全部显示在单元格内,我们需要的网址和书签标题,已经基本显示出来,删除我们不需要的列,得到下面的大致内容。(我们需要的网址是.html结尾的,那个.ico结尾的不是我们需要的,果断删除!)
 8/8
8/8经过观察不难发现,标题的前后分别有个“”和“”特殊符号,相同的方式,利用这个符号进行分列处理,删除多余列,最终得到我们需要的信息。
 注意事项
注意事项生活在于发现和思考。
喜欢这篇经验的请猛点“大拇指”和“加关注”。
书签超链接版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_1016215.html