 订阅
订阅spss教程:K-Means聚类(快速聚类)
来源:网络收集 点击: 时间:2024-08-09【导读】:
层次聚类的每一步都要重新计算每个距离,对计算机的要求高,K-Means聚类也称快速聚类,仍然是以距离作为亲疏指标。方法/步骤1/3分步阅读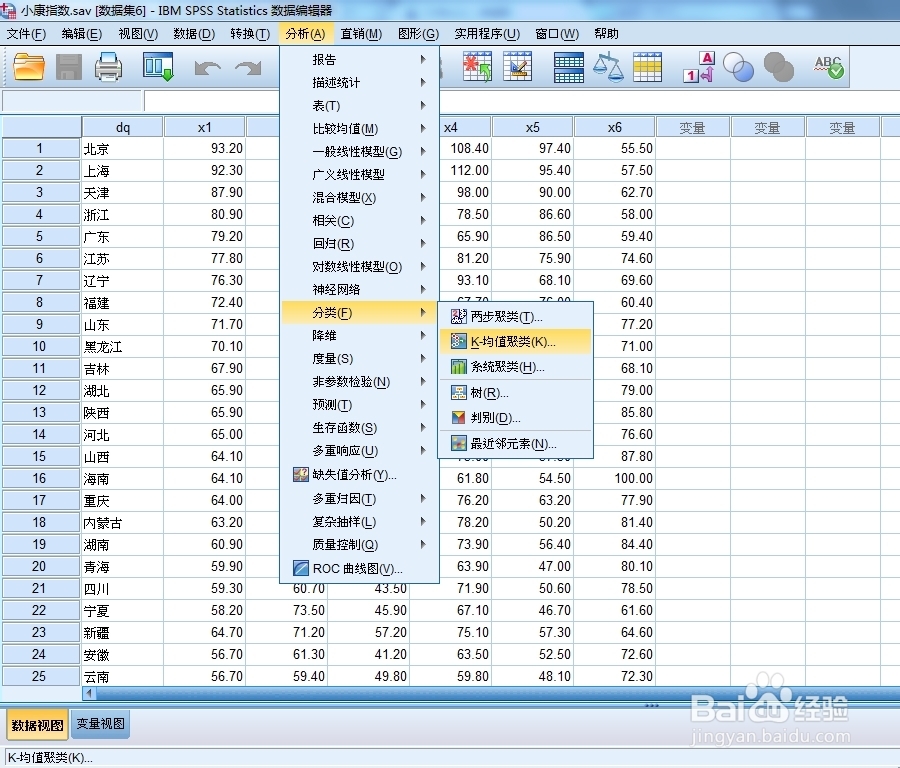
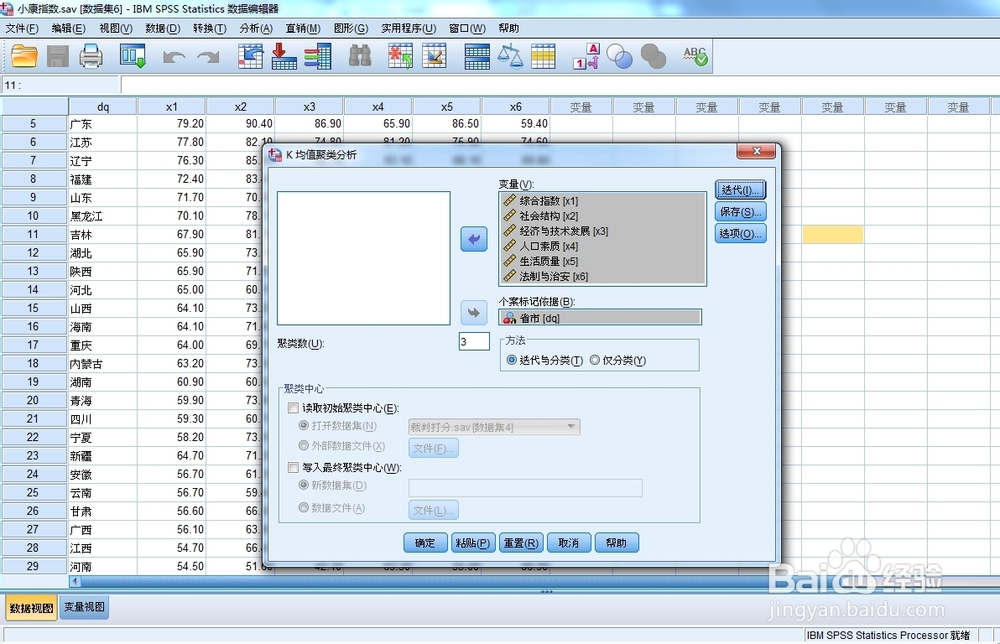 2/3
2/3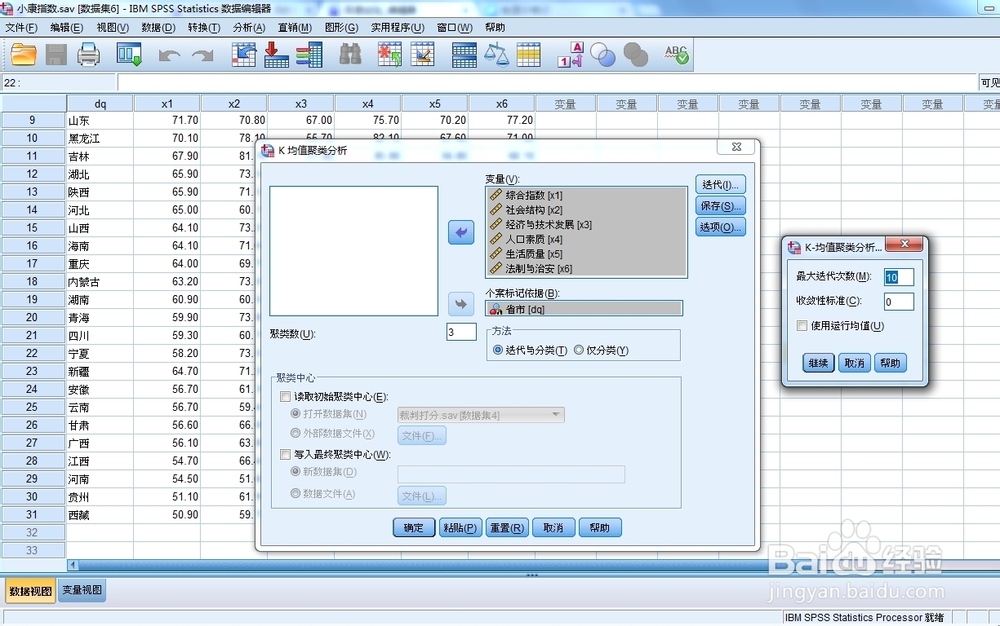

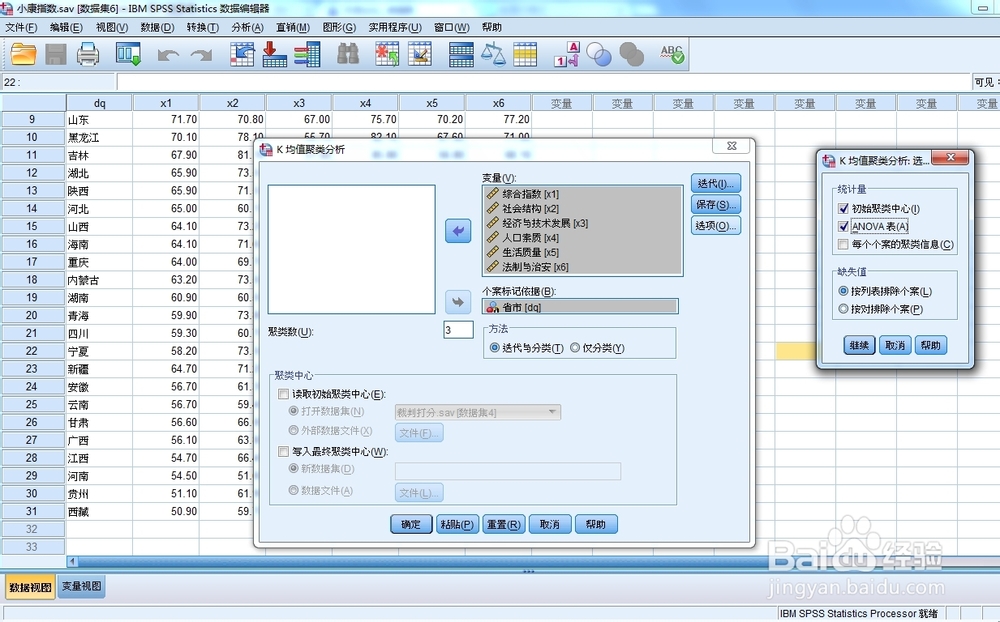 3/3
3/3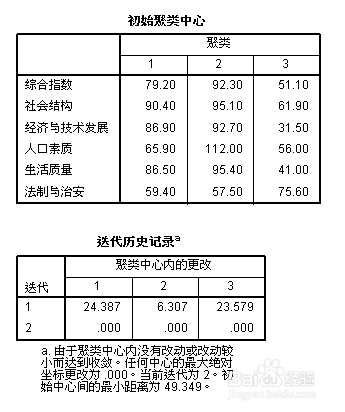
 k-means
k-means
K-Means聚类需要用户先确定聚类数目,只有唯一的解,输入3,表示分为3类。
迭代与分类:表示聚类分析的每一步都重新确定类中心点(spss默认),仅分类表示类中心点始终为初始类中心点,此时仅进行一次迭代。
2/3迭代次数和收敛性标准均是判断快速聚类终止的标准,通常情况下不改变软件自带的数。
“保存”选项中的“聚类成员”即为聚类分析后的分类结果保存在原始数据窗口中。
“选项”中的“初始聚类中心”、“单因素方差分析”是最后显示的结果。
3/3结果分析:“初始聚类中心”显示最初始的6维空间的类中心,“迭代历史记录”中表示第1次迭代后,类的中心点分别偏移24.387、6.307、23.579,第二次迭代后,偏移量等于设置中输入的“收敛性标准”中的“0”,故停止聚类分析。
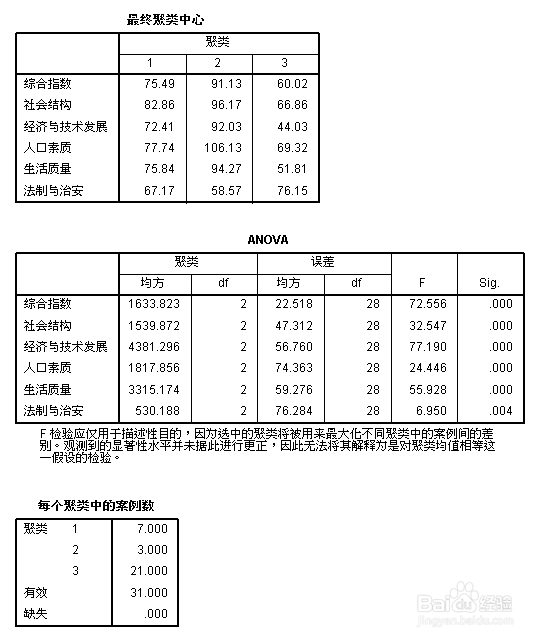
第二个图:显示最终的聚类中心的6维空间数值;又单因素方差分析知,聚类后的3类之间存在显著的差别;第一、二、三类的个案数分别是7、3、21。
k-means 版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_1094112.html
上一篇:safari如何恢复历史记录删除
下一篇:WPS中如何插入竖向文本框