 订阅
订阅网页采集翻页无下一页,数字翻页解决方法
来源:网络收集 点击: 时间:2024-03-02首先我们打开一个这样的网页
打开之后翻页页面如下图显示
 2/13
2/13可以在某狐浏览器看下这个翻页的源码,如下图所示:
当前页在第一页,源码是span标签开头的,其他页面是a标签开头的。
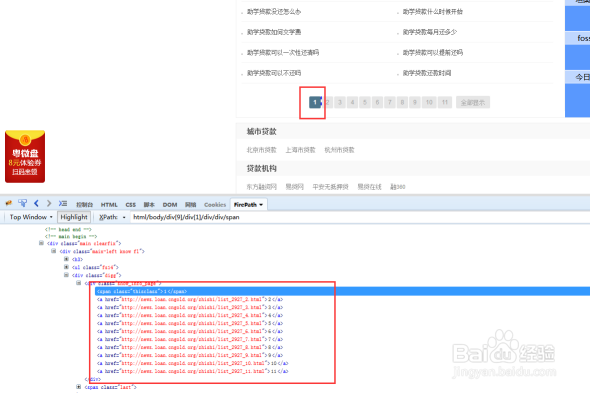 3/13
3/13我们再翻到其他页,看看是不是也是这个特点。可以看到当前页在第7页,第7页的源码显示是span开头的,其他页码变为a标签开头的。
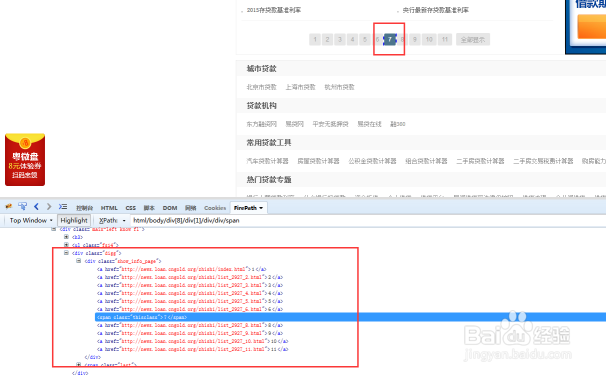 4/13
4/13我们可以根据这个特点相应的写xpath,然后手动创建翻页循环。
我们需要让八爪鱼选择的是当前页的下一页,也就是span元素的后面一个元素,
这时我们需要检验如何泛购写Xpath才能准确定位到当前页。
借助于火狐浏览器,我们先定位span标签
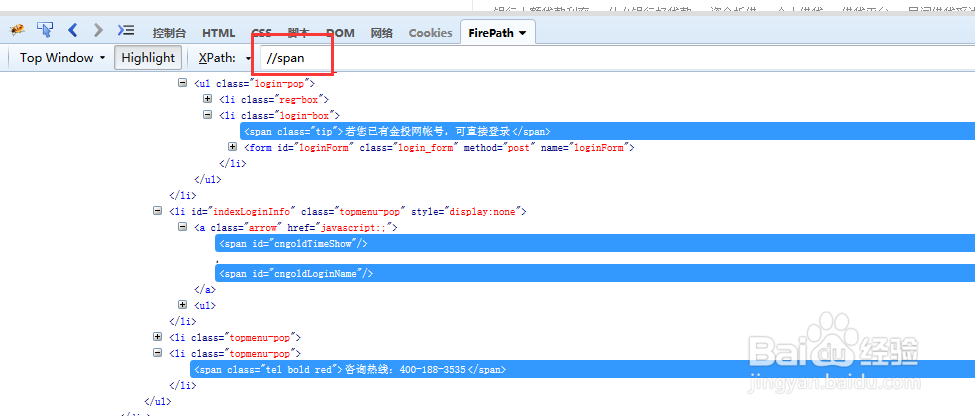 5/13
5/13看上图这个页面里面span标签有很多,我们再看一下原本需要的span标签,可以看到span标签里面的class属性,根据这个属性定位。
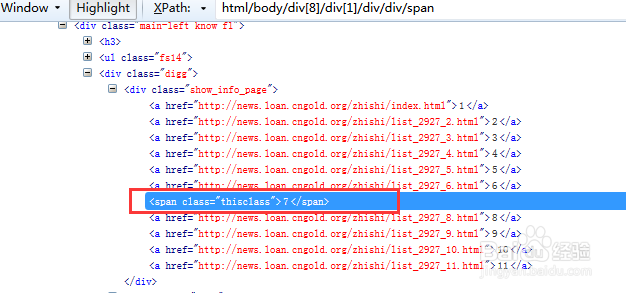 6/13
6/13如下图,//span即能定位到我们需要的当前页
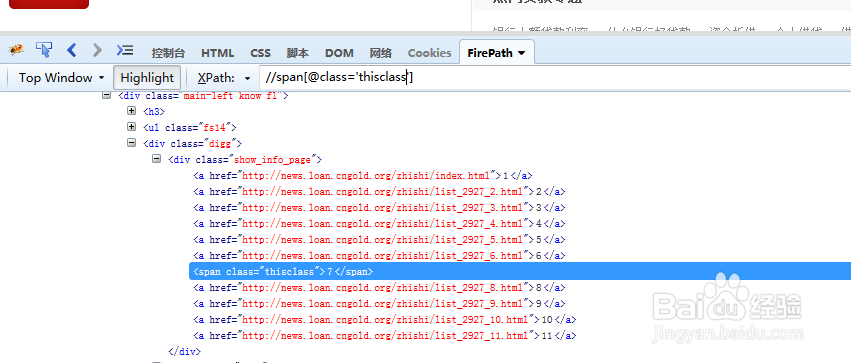 7/13
7/13接下来我们打开八爪鱼中的Xpath工具,生成选择后面元素的Xpath
 8/13
8/13利用following-sibling定位当前页的下一页,后面元素是a,我们将a加在刚刚生成的Xpath后
//span/following-sibling::a可以定位到当前span下面的所有兄弟元素,注意这个following-sibling后面的::是固定格式
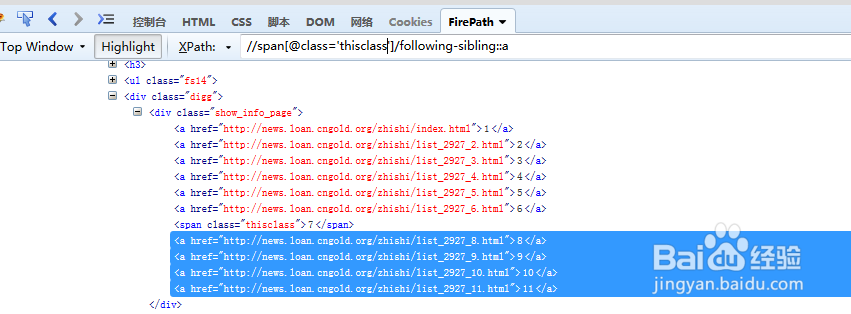 9/13
9/13由于我们只需要定位到当前页的下一页,所以只需要定位到第一个a标签,即给a一个标号//span/following-sibling::a
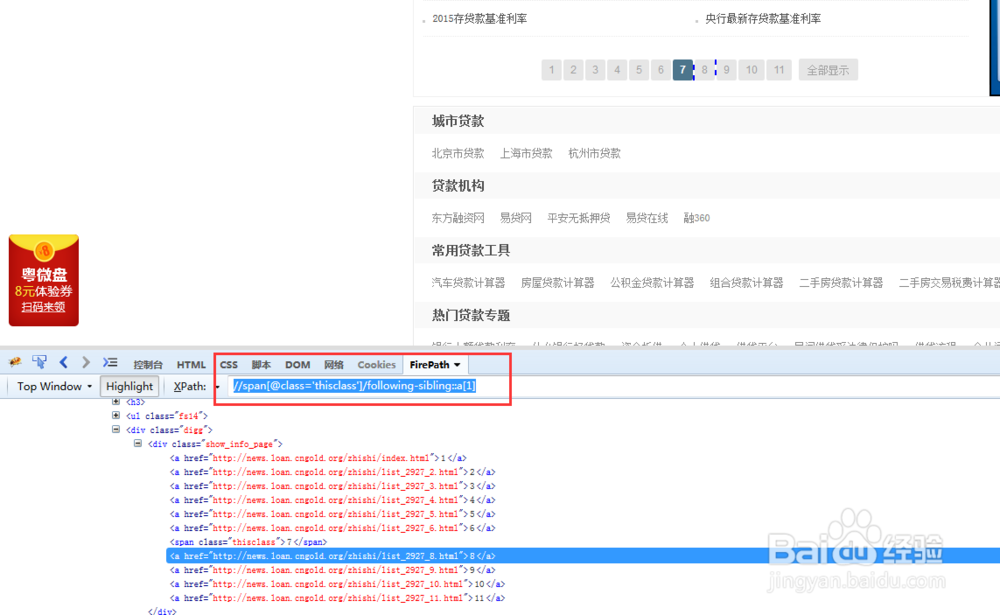 10/13
10/13可以看到当前页为第7页,现在定位到了它的下一页即第8页。
接下来我们在八爪鱼里面手动创建翻页循环
我们先往流程设计器里面拖入一个循环步骤,再在高级里面选择单个元素,并把写好的xpath路径//span/following-sibling::a复制到单个元素里面去,点击保存之后可以看到循环列表为当前页的下一页即第2页
 11/13
11/13做好之后再往循环里面拖入一个点击元素的步骤,并在高级里面勾选点击当前循环中设置的元素,并保存。
 12/13
12/13设置好之后可耻国诉以在流程设计器中验证我们做的翻页循环是否正确。
 13/13
13/13选择点击元素,可以看到下方浏览器正常翻页。
 网页采集翻页采集
网页采集翻页采集 版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_214970.html