 订阅
订阅机器学习——fetch_20newsgroups离线下载
来源:网络收集 点击: 时间:2024-05-31下载fetch_20newsgroups数据集。
 2/12
2/12按‘windows’加‘E’快捷键打开资源管理界面。
 3/12
3/12打开C盘。
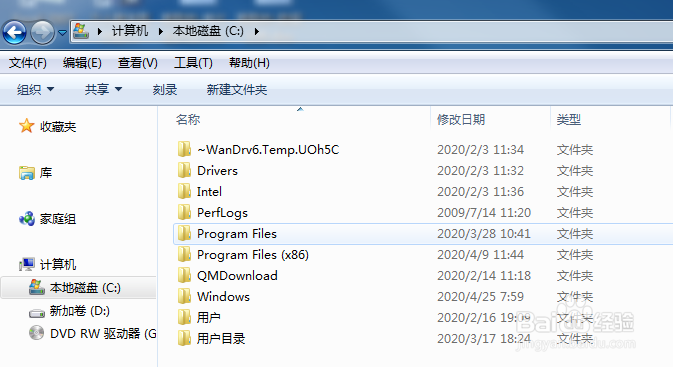 4/12
4/12选择用户文件夹。
 5/12
5/12选择Administrator文件夹。
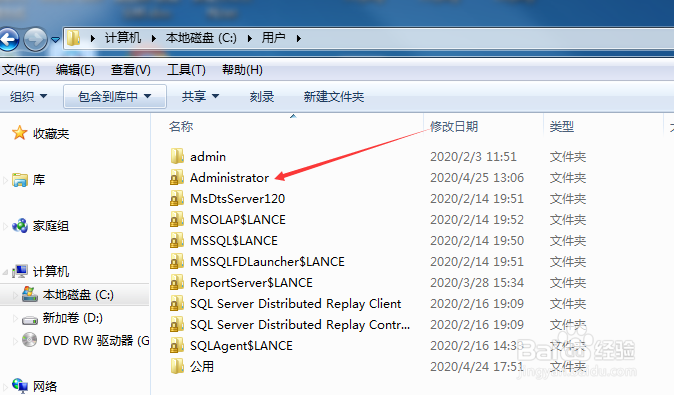 6/12
6/12选择scikit_learn_data文件夹。
 7/12
7/12首次打开后是个空白文件夹。
 8/12
8/12打开此文件夹后,回到Jupyter下,导入相应模块。
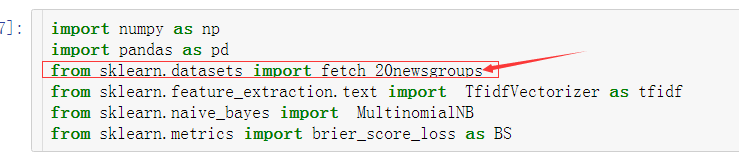 9/12
9/12运行 fetch_20newsgroups(subset=all)语句,会自动在上面打开的文件夹中创建一个文件夹。
 10/12
10/12自动创建的创建文件夹。
 11/12
11/12打开创建的文件夹。
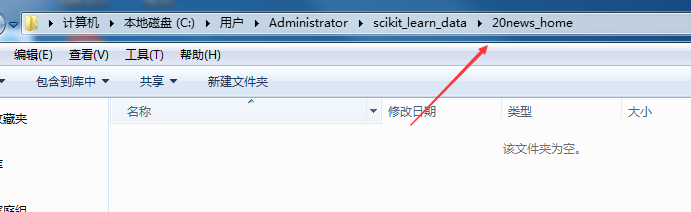 12/12
12/12将下载好的数据集,复制到此文件夹中。
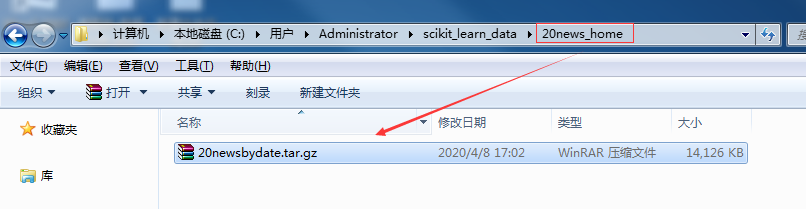 打开Anaconda的安装目录1/21
打开Anaconda的安装目录1/21根据自己安装Anaconda时选择的路径,打开安装文件夹目录。
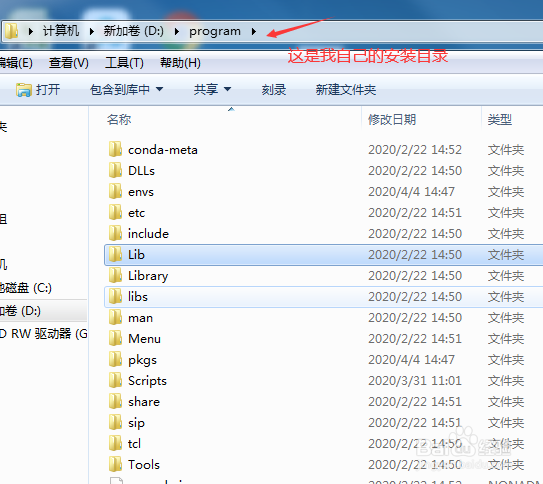 2/21
2/21选择Lib文件夹。
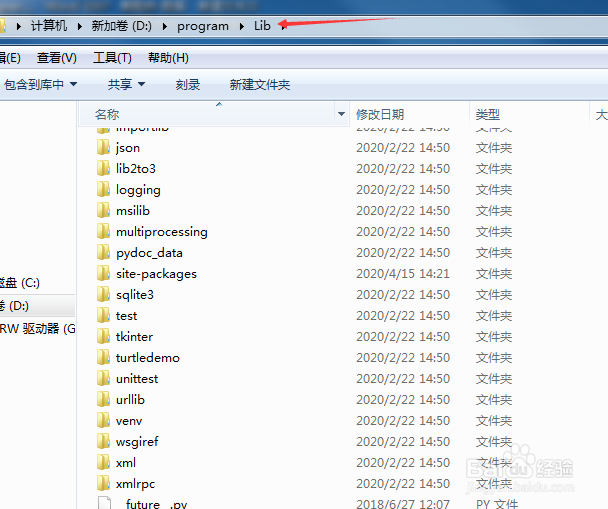 3/21
3/21选择site-packages文件夹。
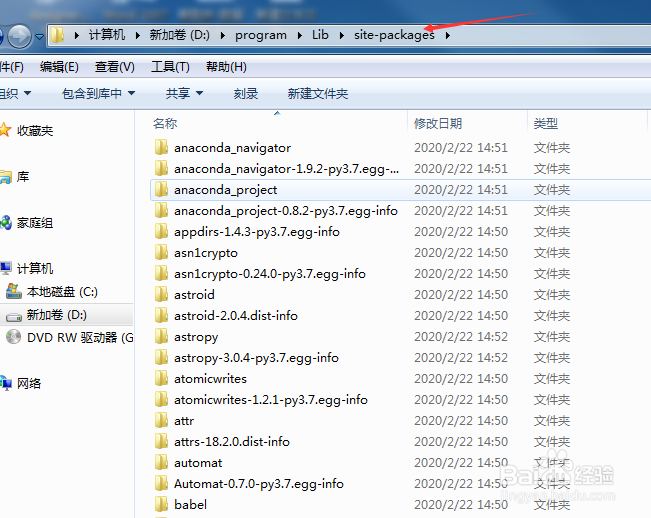 4/21
4/21选择sklearn文件夹。
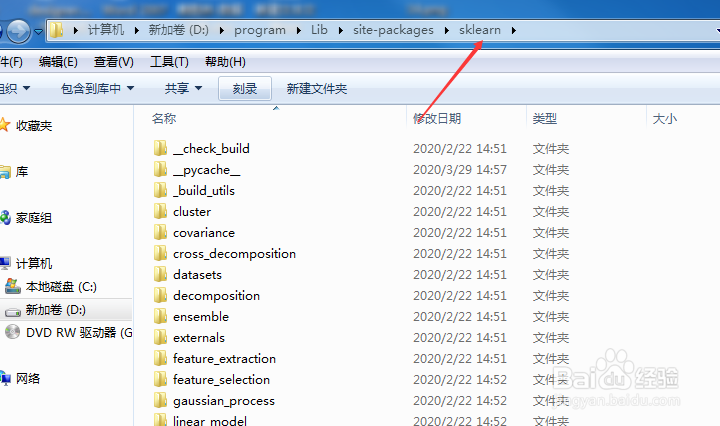 5/21
5/21选择datasets文件夹。
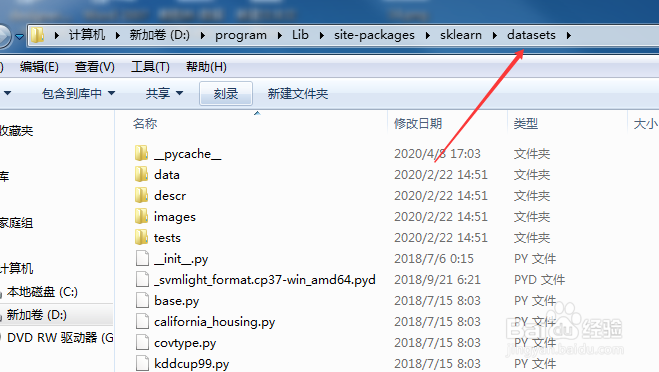 6/21
6/21打开spyder软件。
 7/21
7/21将datasets文件夹下的twenty_newsgroups.py拖动到spyder中。
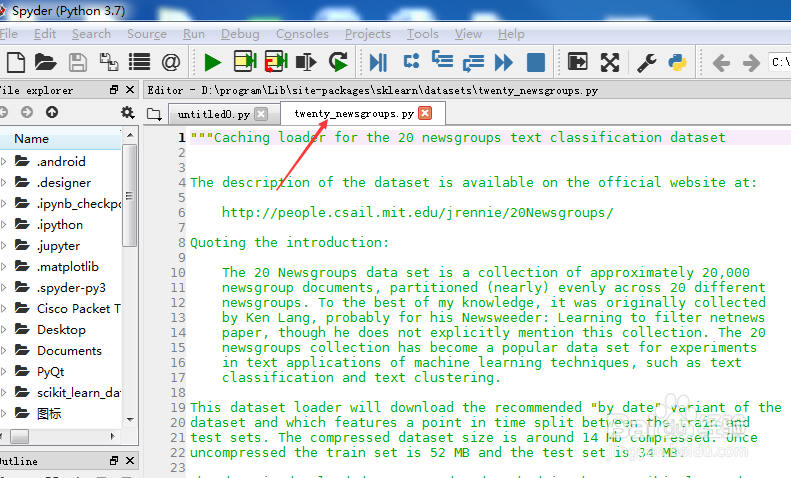 8/21
8/21找到‘download_20newsgroups’函数。
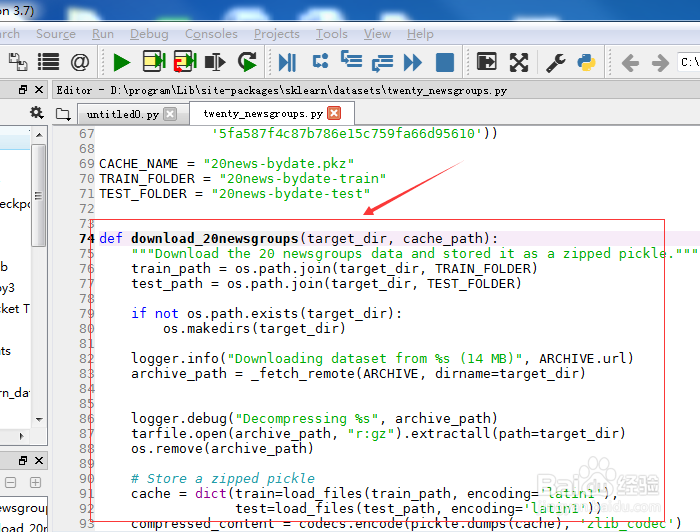 9/21
9/21下载语句部分如图示。
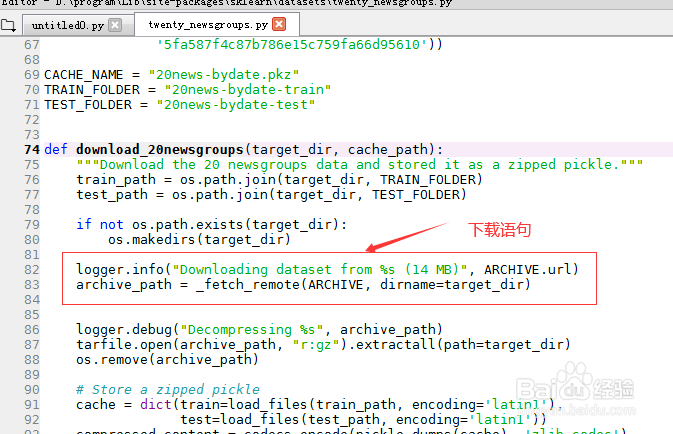 10/21
10/21解压语句部分如图示。
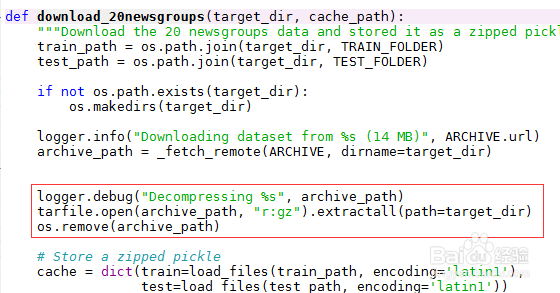 11/21
11/21由于已经自己下载好数据集,因此需要注释掉下载数据集的代码。
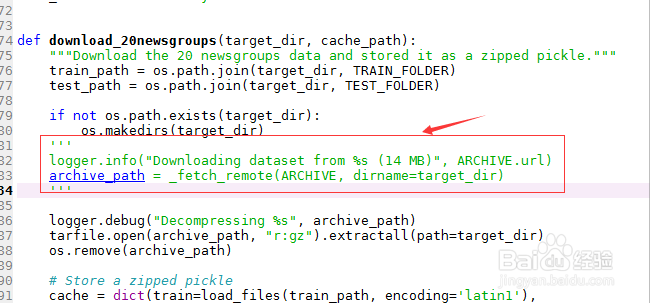 12/21
12/21将刚刚存放的数据集的文件目录存入archive_path变量。
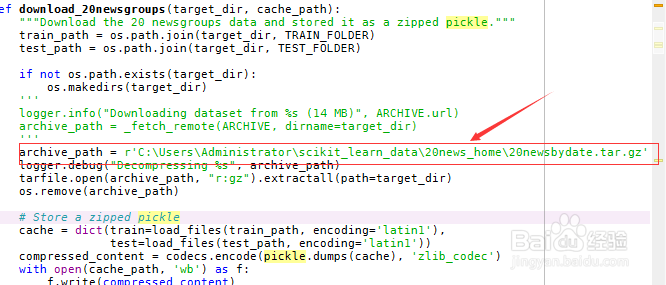 13/21
13/21修改完毕后并保存。
14/21再次运行 fetch_20newsgroups(subset=all)语句,解压下载的数据集文件。
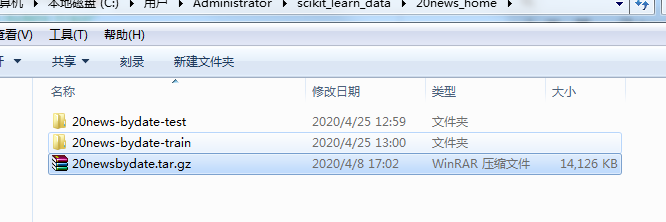
 15/21
15/21执行过程中,会新建两个文件。
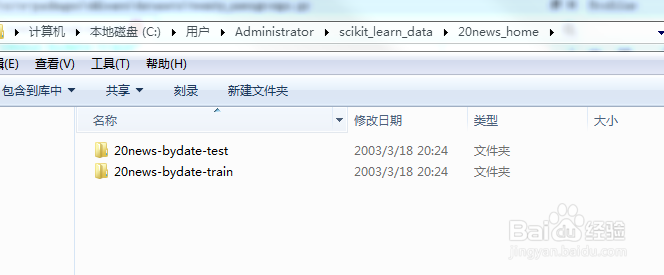
 16/21
16/21解压完成后,会自动删除压缩文件。
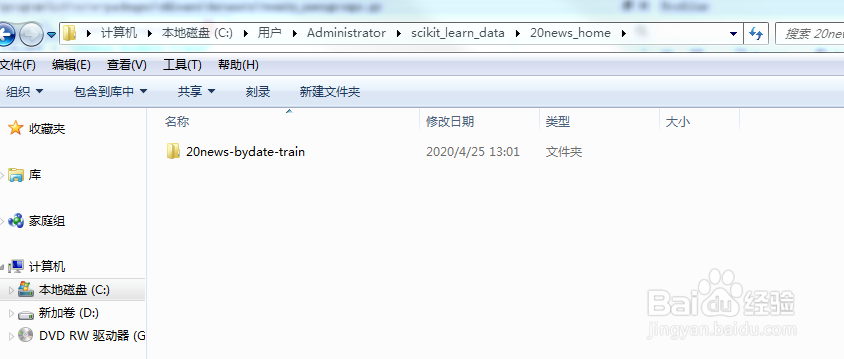
 17/21
17/21接着会自动删除刚刚生成的两个文件夹。
 18/21
18/21最终只剩下一个后缀名为pkz的文件。
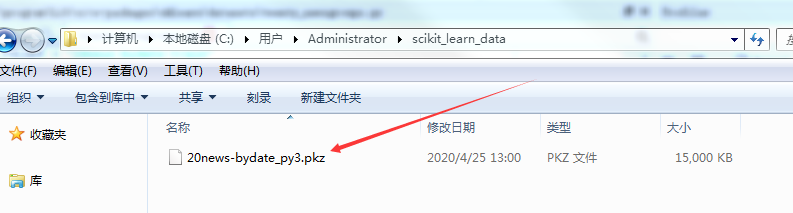 19/21
19/21到此为止fetch_20newsgroups数据集添加完成。
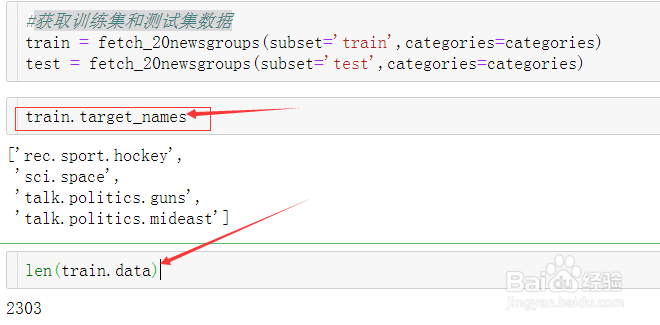
20/21获取训练集和测试集数据。
 21/21
21/21调用数据效果如下。
 PYTHON机器学习
PYTHON机器学习 版权声明:
1、本文系转载,版权归原作者所有,旨在传递信息,不代表看本站的观点和立场。
2、本站仅提供信息发布平台,不承担相关法律责任。
3、若侵犯您的版权或隐私,请联系本站管理员删除。
4、文章链接:http://www.1haoku.cn/art_865252.html